
Josh Payne
Ste·ga·no·graph·y / stegəˈnägrəfi / (noun): the practice of concealing messages or information within other nonsecret text or data.
Steganography has been used for ages to communicate information in a hidden manner. You may think: how is this different than cryptography? Isn’t cryptography a very well-studied field in which two individuals aim to share information with each other without an eavesdropper being able to discover this information? Indeed, these two areas are very similar, but there’s a magical property of steganography that takes information sharing to a whole different level: the information is shared without an eavesdropper even knowing that anything secret is being shared. What’s the use of, say, Shor’s algorithm (for breaking RSA encryption in polynomial time using a supercomputer) if you don’t even know what to decrypt?
Steganography has long been associated with painting and visual art. Painters often hide signatures, self-portraits, and other secret messages within their works as a sort of “inside joke”. One such example of this is Jackson Pollock’s “Mural”, wherein Pollock hid his entire name in plain sight in the curvatures of the work.

Until recently, however, computational steganography methods for images (such as appending bits at the end of a .jpg file or applying mathematical functions to select RGB pixel values) have been easy to detect and uncover, and hand-crafted ones are difficult and not scalable.
In 2017, Shumeet Baluja the idea of using deep learning for image steganography in his paper “Hiding Images in Plain Sight: Deep Steganography“. In this paper, a first neural network (the hiding network) takes in two images, a cover and a message. The aim of the hiding network is to create a third image, a container image, that is visually similar to the cover image and is able to be used by a second neural network (the revealing network) to reconstruct the message image via the revealed image (without any knowledge of either the original message or the original cover). The loss is defined by how similar the cover and container images are and how similar the message and revealed images are. The results were astounding: the network was able to create container images that looked very much like the cover yet allowed the revealing network to reconstruct the message very closely.

While this result was very interesting, we felt that the utility of steganography specifically for images is limited.
The question arises: what are the limits for this approach in other information domains?
More specifically, what we aimed to apply this approach to was the domain of human language and text, which could be a stepping stone to implementing this procedure for general information. Text is harder to perform steganography with: images are dense while text is sparse; images aren’t affected much by small changes in pixel values while text is greatly affected by small changes in token values. While various methods for conducting text-based steganalysis exist, they face substantial challenges: (1) these classical heuristic-based approaches are often easy to decode, because they leverage fixed, easily reversible rules, and (2) these algorithms do not exploit any of the structural properties of the text, resulting in hidden messages that are not semantically correct or coherent to humans.
Recent deep learning approaches rely on using generative models to hide the “secret” text in meaningless groupings of words. Here, we want to propose using a transformer-based approach to address both problems at once. We explore using a transformer to combine the desired secret text with some human-readable, coherent cover text in order to generate a new container text that both properly encodes the hidden message inside of it and is nearly identical to the cover text, retaining the cover text’s original semantic structure and legibility. In addition to the transformer used for encoding, we leverage a second transformer model to decode the container text and recover the hidden message.
Because transformers are big and bulky, we tested our luck with a much simpler 1D-convolution character-based approach.

In this character-based approach, the idea is that a model would learn a statistical profile of character choices in a string of text and modify the characters in a way that sends a signal capturing the hidden message through character additions, substitutions, or removals.
A trivial example in which the message is two bits is considered. To communicate the secret message, our function is the length of the container message modulo 4. More specifically, let 


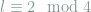
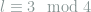
Cover: I can not believe my eyes, what I saw in the forest was far beyond the reaches of my imagination.
Secret: meet at river tomorrow at sunset.
Container: I mac now bleiave mye eey, waht ra sa inn tee freost ws fara beymdo tee racheas o fem imaingaiton.
Revealed Secret: wemt a th rivre tomowro tt snseht.
However, an interesting (likely unsolved and very difficult) information-theoretic question arises in this area: given an information domain (like images, text, etc.), how much secret information can a model hide in given cover information in the average case? We started to see that with larger secret message input sizes and a static cover message size, the model had an increasingly difficult time hiding the information and reconstucting the hidden message. How good it was at each depended on how we weighted the two tasks in the loss function.
Next, we decided to investigate a more hefty model for performing steganography in text. The primary approach we propose to tackle the challenge of text-based steganography consists of leveraging two NMT (Neural Machine Translation) models: one transformer model to encode the hidden message and a second model to decode it. We hypothesize that this transformer-based approach can potentially succeed at encoding a secret text within a cover text to produce a container text that closely matches the semantic structure of the cover text. An additional nice thing about this is that no custom dataset is needed: any collection of sentences or phrases and random generation of secret messages will do.
What does “similarity” between cover and container in this case mean? We don’t have a simple metric anymore like edit distance or L2 norm between pixel values. In our new scheme, the sentence “Don’t eat, my friends!” and “Don’t eat my friends!” mean very different things, whereas “Don’t eat, my friends!” and “Please abstain from feeding yourselves, comrades of mine!” essentially mean the same thing. For ascertaining a metric of similarity, we leverage BERT (Bidirectional Embedded Representations from Transformers), a pretrained model that represents sentences as real-valued vectors where the cosine similarity between two vectors is a good indication of how similar the sentences are in meaning.

The results presented in Neural Linguistic Steganography, the work most closely related to our own, indicate that state-of-the-art transformer-based language models such as GPT-2 can be leveraged to generate convincing cover texts to hide secret messages. In our implementation, our first NMT transformer model reads in the concatenated secret message (four digits in base 10) and cover text and proceeds to translate them into a container text. Our second transformer reads in the container text and translates it into a reconstruction of the original secret message. Again, the loss function we use consists of a linear combination of the similarity functions between the cover text and the container text (using BERT to produce Loss_Stego), along with the edit distance between the reconstructed secret message and the original secret message. The loss function is formulated as

where 



We found that the model that we used, an LSTM seq2seq model with attention and a hidden size of 512 for encoder and decoder for the hiding network and revealing network, was not powerful enough to generate good containers and was faulty in reconstructing the secret message. The loss started after around 100 examples at 1.1 converged after around 200,000 examples at around 0.85. We additionally hypothesize that a low loss is likely the result of a generative adversarial model for BERT: finding sentences that are meaningless to humans but have small cosine similarity in their embeddings against cover texts as evaluated by BERT. Below is one output example:
Cover: celebrate the opportunity you have to eat this.
Secret: 8 4 1 4.
Container: murdoch cleverness germane obeng blessing pedals ampoule mbi mbi jharkhand ampoule coring substantive substantive tranquil steadfast.
Revealed Secret: 8 4 4 4.
However, we also feel that with a sufficiently powerful model (such as using BERT for the encoder and GPT-2 for the decoder) and enough compute power, a model could start to perform useful steganography on textual and general information. This technique could potentially revolutionize communication where there exist adversarial eavesdroppers, especially in the quantum era of fast decryption of common cryptographic protocols. This implementation is left as future work to folks who have an abundance of compute resources.
Code for the seq2seq model is viewable in this Colab.
Note that while text is very sparse, the same technique can be used on dense audio files for spoken language transmission and data hiding. The technique would be similar to the convolutional approach proposed for images on a 2D spectrogram or 1D convolution over the waveform (e.g. WaveNet) and would have wide implications for covert communications.
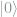 and
and 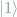 . With
. With 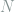 qubits, there are
qubits, there are  such quantum states and each of them has
such quantum states and each of them has  for
for  . Quantum gates in a quantum computer transform and interfere these states in a way that is hard to be simulated by a classical computer.
. Quantum gates in a quantum computer transform and interfere these states in a way that is hard to be simulated by a classical computer.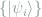 with a probability distribution
with a probability distribution 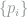 . This ensemble is usually represented as a density matrix
. This ensemble is usually represented as a density matrix  with
with  entries in it.
entries in it.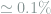 ) in the noisy channels. Second,
) in the noisy channels. Second, 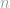 -qubit noisy channels are composition of single-qubit noisy channels. In other word, it is assumed that noise in a qubit is independent to other qubits.
-qubit noisy channels are composition of single-qubit noisy channels. In other word, it is assumed that noise in a qubit is independent to other qubits.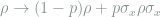 , where p is the noise level,
, where p is the noise level, 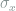 is the Pauli X matrix, it is found that the maximum output entropy growth approximately logarithmically. It means that, while it takes
is the Pauli X matrix, it is found that the maximum output entropy growth approximately logarithmically. It means that, while it takes  complex numbers to track a full density matrix, it is possible to tack a compressed representation with only
complex numbers to track a full density matrix, it is possible to tack a compressed representation with only  numbers. The compression rate is approximately
numbers. The compression rate is approximately 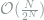 . In the depolarizing channel defined by
. In the depolarizing channel defined by  , where
, where 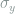 is the Pauli Y matrix and
is the Pauli Y matrix and 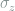 is the Pauli Z matrix, it is harder to find the exact maximum output entropy. But it is found that the entropy is upper bounded by a quantity that grows approximately logarithmically. Thus, the compression rate is also approximately
is the Pauli Z matrix, it is harder to find the exact maximum output entropy. But it is found that the entropy is upper bounded by a quantity that grows approximately logarithmically. Thus, the compression rate is also approximately 



 ), and obtain 81.6% for the ancient set and 82.5% for the modern one.
), and obtain 81.6% for the ancient set and 82.5% for the modern one.






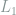 norm is used instead of
norm is used instead of  to encourage sparsity (for numerical tractibility).
to encourage sparsity (for numerical tractibility).
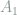 ,
, 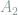 , …,
, …,  and a quantum state represented by a density matrix
and a quantum state represented by a density matrix  of a low rank r. Through the m different measurements represented by the operators
of a low rank r. Through the m different measurements represented by the operators 
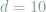 (
(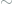 3 qubits), with varying ranks (
3 qubits), with varying ranks ( ), we show the minimum error one can achieve with m random measurements, as in Fig. 1. As a sanity check, we first note the obvious fact that minimum error should decrease with respect to the number of measurements. Moreover, when the target matrix is not full-rank, the error can be reduced to 0 without involving 100 measurements (corresponding to the total degrees of freedom for a
), we show the minimum error one can achieve with m random measurements, as in Fig. 1. As a sanity check, we first note the obvious fact that minimum error should decrease with respect to the number of measurements. Moreover, when the target matrix is not full-rank, the error can be reduced to 0 without involving 100 measurements (corresponding to the total degrees of freedom for a  matrix).
matrix).

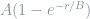 , which is indeed linear in r at low-rank limit and thus consistent with the literature.
, which is indeed linear in r at low-rank limit and thus consistent with the literature.
 , as predicted in classical CS [2] and different from the bounds for quantum case [1]. This is the effect of our relaxation of the constraint on
, as predicted in classical CS [2] and different from the bounds for quantum case [1]. This is the effect of our relaxation of the constraint on  ) and phase (
) and phase (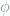 ) respectively in a certain basis set
) respectively in a certain basis set  , where
, where  can stand for any Pauli basis defined according to the measurement axis of qubit
can stand for any Pauli basis defined according to the measurement axis of qubit 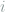 . With index
. With index  , the Boltzmann weight for a particular configuration is given by:
, the Boltzmann weight for a particular configuration is given by:![p_{\kappa}(\bm{\sigma},\bm{h}) = \exp\bigg[\sum_{ij}W^{\kappa}_{ij}h_{i}\sigma_{j} + \sum_{j} b^{\kappa}_{j}\sigma_{j} +\sum_{i} c^{\kappa}_{i}h_{i}\bigg],](https://s0.wp.com/latex.php?latex=p_%7B%5Ckappa%7D%28%5Cbm%7B%5Csigma%7D%2C%5Cbm%7Bh%7D%29+%3D+%5Cexp%5Cbigg%5B%5Csum_%7Bij%7DW%5E%7B%5Ckappa%7D_%7Bij%7Dh_%7Bi%7D%5Csigma_%7Bj%7D+%2B+%5Csum_%7Bj%7D+b%5E%7B%5Ckappa%7D_%7Bj%7D%5Csigma_%7Bj%7D+%2B%5Csum_%7Bi%7D+c%5E%7B%5Ckappa%7D_%7Bi%7Dh_%7Bi%7D%5Cbigg%5D%2C&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
 denotes the states of the hidden nodes, with
denotes the states of the hidden nodes, with  . We subsequently obtain the distribution over
. We subsequently obtain the distribution over  , i.e.
, i.e.  by marginalizing the dependence on
by marginalizing the dependence on  . The resulting wavefunction is given by:
. The resulting wavefunction is given by:


 denotes the measurement statistics in the
denotes the measurement statistics in the  is the diagonal element of the density matrix in the
is the diagonal element of the density matrix in the 



