[display-posts category=”EE376A (Winter 2019)” posts_per_page=1000 order=”ASC” orderby=”title”]
EE376A (Winter 2019)
Hopfield Networks
EE376A (Winter 2019)Jordan Alexander
(Note: I’d recommend just checking out the link to my personal site: https://jfalexanders.github.io/me/articles/19/hopfield-networks, the version there has a few very useful side notes, images, and equations that I couldn’t include here)
These days there’s a lot of hype around deep learning. We have these things called “deep neural networks” with billions of parameters that are trained on gigabytes of data to classify images, produce paragraphs of text, and even drive cars. But how did we get here? And why are our neural networks built the way they are? In order to answer the latter, I’ll be giving a brief tour of Hopfield networks, their history, how they work, and their relevance to information theory. By studying a path that machine learning could’ve taken, we can better understand why machine learning looks like it does today.
I. A brief history of artificial neural networks
While neural networks sound fancy and modern, they’re actually quite old. Depending on how loosely you define “neural network”, you could probably trace their origins all the way back to Alan Turing’s late work, Leibniz’s logical calculus, or even the vague notions ofGreek automata.
In my eyes, however, the field truly comes into shape with two neuroscientist-logicians: Walter Pitts and Warren McCullough. These two researchers believed that the brain was some kind of universal computing device that used its neurons to carry out logical calculations. Together, these researchers invented the most commonly used mathematical model of a neuron today: the McCulloch–Pitts (MCP) neuron.
These neural networks can then be trained to approximate mathematical functions, and McCullough and Pitts believed this would be sufficient to model the human mind. Now, whether an MCP neuron can truly capture all the intricacies of a human neuron is a hard question, but what’s undeniable are the results that came from applying this model to solve hard problems.
The first major success came from David Rumelhardt’s group in 1986, who applied the backpropagation algorithm to train a neural network for image classification and showed that neural networks can learn internal representations of data. Before we examine the results let’s first unpack the concepts hidden in this sentence:training/learning, backpropagation, and internal representation.
Let’s start with learning. While learning conjures up images of a child sitting in a classroom, in practice, training a neural network just involves a lot of math. At its core, a neural networks is a function approximator, and “training” a neural network simply means feeding it data until it approximates the desired function. Sometimes this function is a map from images to digits between 0-9, and sometimes it’s a map from blocks of text to blocks of text, but the assumption is that there’s always a mathematical structure to be learned.
Training a neural network requires a learning algorithm. Of these, backpropagation is the most widely used. The basic idea of backpropagation is to train a neural network by giving it an input, comparing the output of the neural network with the correct output, and adjusting the weights based on this error.
Backpropagation allows you to quickly calculate the partial derivative of the error with respect to a weight in the neural network. This roughly corresponds to how “significant” this weight was to the final error, and can be used to determine by how much we should adjust the weight of the neural network. If fed enough data, the neural network learns what weights are good approximations of the desired mathematical function.
There’s a tiny detail that we’ve glossed over, though. The original backpropagation algorithm is meant for feed-forward neural networks. That is, in order for the algorithm to successfully train the neural network, connections between neurons shouldn’t form a cycle. We call neural networks that have cycles between neurons recurrent neural networks, and, it at least seems like the human brain should be closer to a recurrent neural network than to a feed-forward neural network, right? Yet, backpropgation still works. While researchers
later generalized backpropagation to work with recurrent neural networks, the success of backpropgation was somewhat puzzling, and it wasn’t always as clear a choice to train neural networks. So what does that mean for our neural network architectures?
In the present, not much. Regardless of the biological impossibility of backprop, our deep neural networks are actually performing quite well with it. But a few years ago, there was an abundance of alternative architectures and training methods that all seemed equally likely to produce massive breakthroughs.
One of these alternative neural networks was the Hopfield network, a recurrent neural network inspired by associative human memory. The hope for the Hopfield human network was that it would be able to build useful internal representations of the data it was given. That is, rather than memorize a bunch of images, a neural network with good
internal representations stores data about the outside world in its own, space-efficient internal language. There are a few interesting concepts related to the storage of information that come into play when generating internal representations, and Hopfield networks illustrate them quite nicely. As for practical uses of Hopfield networks, later in this post we’ll
play around with a Hopfield network to see how effective its own internal representations turned out to be.
II. What is a Hopfield network?
Imagine a neural network that’s designed for storing memories in a way that’s closer to how human brains work, not to how digital hard-drives work. We’d want the network to have
the following properties:
- Associative: Memories are tied to each other and remembering one thing triggers another memory.
- Robust: Even when the network is damaged it still retains a good portion of its functionality. For example, if you were to damage your digital hard drive, it would often be a complete loss, but the human brain–even under traumatic injuries–is still able to retain a sigificant portion of its functionality.
To make this a bit more concrete, we’ll treat memories as binary strings with B bits, and each state of the neural network will correspond to a possible memory. This means that there will be a single neuron for every bit we wish to remember, and in this model, “remembering a memory” corresponds to matching a binary string to the most similar binary string in the list of possible memories. Example: Say you have two memories {1, 1, -1, 1}, {-1, -1, 1, -1} and you are presented the input {1, 1, -1, -1}. The desired outcome would be retrieving the memory {1, 1, -1, 1}.
Now, how can we get our desired properties? The first, associativity, we can get by using a novel learning algorithm. Hebbian learning is often distilled into the phrase “neurons that fire together wire together”,
So, for example, if we feed a Hopfield network lots of (images) of tomatoes, the neurons corresponding to the color red and the neurons corresponding to the shape of a circle will activate at the same time and the weight between these neurons will increase. If we later feed the network an image of an apple, then, the neuron group corresponding to a circular shape will also activate, and the we’d say that the network was “reminded” of a tomato.
The second property, robustness, we can get by thinking of memories as stable states of the network:
If a certain amount of neurons were to change (say, by an accident or a data corruption event), then the network would update in such a way that returns the changed neurons back to the stable state. These states correspond to local “energy” minima, which we’ll explain later on.
Hopfield networks can be used to retrieve binary patterns when given a corrupted binary string by repeatedly updating the network until it reaches a stable state. If the weights
of the neural network were trained correctly we would hope for the stable states to correspond to memories. Intuitively, seeing some amount of bits should “remind” the neural network of the other bits in the memory, since our weights were adjusted to satisfy the Hebbian principle “neurons that fire together wire together”
Now that we know how Hopfield networks work, let’s analyze some of their properties.
III. Storing information in Hopfield networks
Hopfield networks might sound cool, but how well do they work? To answer this question we’ll explore the capacity of our network (Highly recommend going to: https://jfalexanders.github.io/me/articles/19/hopfield-networks for LaTeX support). The
idea of capacity is central to the field of information theory because it’s a direct measure of how much information a neural network can store. For example, in the same way a hard-drive with higher capacity can store more images, a Hopfield network with higher capacity can store more memories. To give a concrete definition of capacity, if we assume that the memories of our neural network are randomly chosen, give a certain tolerance for memory-corruption, and choose a satisfactory probability for correctly remembering each pattern in our network, how many memories can we store?
To answer this question we’ll model our neural network as a communication channel. We’re trying to encode N memories into W weights in such a way that prevents:
- The corruption of individual bits
- Stable states that do not correspond to any memories in our list
Example: Say you have two memories {1, 1, -1, 1}, {-1, -1, 1, -1} and you are presented the
input {1, 1, 1, -1}. The desired outcome would be retrieving the memory {1, 1, -1, 1}, corresponding to the most similar memory associated to the memories stored in the neural network.
We can use the formula for the approximation of the area under the Gaussian to bound the maximum number of memories that a neural network can retrieve. Using methods from statistical physics, too, we can model what our capacity is if we allow for the corruption of a certain percentage of memories. Finally, if you wanted to go even further, you could get some additional gains by using the Storkey rule for updating weights or by minimizing an objective function that measures how well the networks stores memories.
IV. What’s next?
Well, unfortunately, not much. Despite some interesting theoretical properties, Hopfield networks are far outpaced by their modern counterparts. But that doesn’t mean their developement wasn’t influential! Research into Hopfield networks was part of a larger
program that sought to mimic different components of the human brain, and the idea that networks should be recurrent, rather than feed-forward, lived on in the deep recurrent neural networks used today for natural language processing.
Outreach
For the outreach portion of the project, I explained the basics of how neural networks stored information through my own blog post and a few articles on distill.pub about machine learning interpretability and feature visualization. The focus of my project was letting the kids play around with neural networks to understand how they generate “internal representations” of the data being fed to them, coupled with a high-level explanation of what this meant.
External Links
For a more detailed blog post, with some visualizations and equations, check out my other blog post on my personal site: https://jfalexanders.github.io/me/articles/19/hopfield-networks
Learning is hard work
EE376A (Winter 2019)Daniel Wennberg[efn_note]If anyone has checked in with this post between 2019-03-24 and 2019-04-03, you might have noticed that it has expanded substantially during that time. The post has now reached its final form. Doing it this way ended up being a necessary part of the well-being component of the course.[/efn_note]
Accounting for around 20 % of the body’s energy consumption, the human brain burns calories at 10 times the rate of your average organ when measured per unit mass.[efn_note]Raichle, M. E., & Gusnard, D. A. (2002). Appraising the brain’s energy budget. Proceedings of the National Academy of Sciences of the United States of America, 99(16), 10237–10239. https://doi.org/10.1073/pnas.172399499[/efn_note] However, its 
Anyone who has felt the heat from the bottom of their laptop has experienced the energy cost of information processing within the current paradigms, but systems capable of learning from their inputs seem to have a particularly high appetite. Perhaps this can tell us something about what learning is at the most fundamental level? Here I will describe an attempt to study perhaps the simplest learning system, the perceptron, as a physical system subject to a stochastic driving force, and suggest a novel perspective on the thermodynamic performance of a learning rule: From an efficiency standpoint we may consider the transient energy expenditure during learning as a cost to be minimized; however, learning is also about producing a state of high information content, which in thermodynamical terms means a far-from-equilibrium and thus highly dissipative state, so perhaps a good learning rule is rather one for which minimizing loss and maximizing heat dissipation goes hand in hand?
To explore this question, we need to know a couple of things about stochastic thermodynamics. This is a rather specialized field of study in its own right, and I’m only aware of three papers in which it is applied to learning algorithms. Therefore, in order that this text may be enjoyed by as many as possible, I will spend the bulk of it laying out the basics of stochastic thermodynamics, how it connects to information theory, and how it can be applied to study learning in the perceptron. I will conclude by presenting one novel result, but this is merely a taste of what it would actually take to properly answer the question posed above.
Thermodynamics and information
Classical thermodynamics is a self-contained phenomenological theory, in which entropy is defined as a measure of irreversibility. If the change in the total entropy of the universe between the beginning and end of some process is zero, it could just as well have happened the other way around, and we say that the process is reversible. Otherwise, it’s a one-way street: the only allowed direction is the one in which entropy increases, and the larger the entropy increase, the more outrageous the reverse process would be, like the unmixing of paint or the spontaneous reassembly of shards of glass. This is the content of the second law of thermodynamics, that total entropy can never decrease, and this is the reason we cannot solve the energy crisis by simply extracting thermal energy (of which there is plenty) from the ocean and atmosphere and convert it into electricity.
However, thermodynamics only makes reference to macroscopic observables such as temperature, pressure, and volume. What if a hypothetical being had the ability to observe each individual molecule in a reservoir of gas and sort them into two separate reservoirs according to their kinetic energy? That would reduce the entropy in the gas and allow us to extract useful work from it. This being is known as Maxwell’s demon, and the resolution to the apparent violation of the second law builds on connections between thermodynamics and the mechanics of the gas molecules as well as the information processing capabilities of the demon, provided by the framework of statistical mechanics. If we assume a probability distribution (or, in physics parlance, an ensemble) over the fully specified states of the fundamental constituents of the system, the entropy of the system can be defined as the corresponding Shannon entropy, in physics called Gibbs entropy. That is, if 


Thermodynamic observables correspond to various means under this distribution, and an equilibrium state is represented by the probability distribution that maximizes entropy for a set of constraints on thermodynamic observables.[efn_note]For example, the internal energy 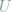

This is perhaps the fundamental sense in which we can claim that information is physical: through entropy, the constraints on the time evolution of a system depend on which information about the system is kept and which is discarded. A more operational take on the same sentiment is that the amount of useful work we can extract from a system depends on the amount of information we have about it.[efn_note]Claims like these have spurred some controversy, mainly because they seem to render thermodynamics subjective. I believe that the objections are based on a subtle misunderstanding of the claim: As long as a system is left to equilibrate with an environment, the thermodynamically relevant entropy is the amount of information ignored when describing the system in terms of the equilibrating potentials only, and this is not a subjective notion. A reduced information entropy due to knowing details that the potentials don’t reveal only becomes thermodynamically operational if we can also manipulate the system-environment interactions based on this information.[/efn_note]
Fluctuations in heat and entropy production[efn_note]For a comprehensive reference, see Seifert, U. (2012). Stochastic thermodynamics, fluctuation theorems and molecular machines. Reports on Progress in Physics, 75(12), 126001. https://doi.org/10.1088/0034-4885/75/12/126001[/efn_note]
The deterministic nature of classical thermodynamics corresponds to our experience in daily life: water predictably freezes at exactly 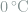

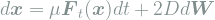
Here, 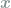
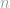






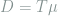

The first law of thermodynamics states that energy is always conserved, and is often written 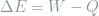
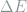

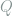
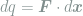


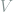


Having defined the heat dissipation 
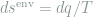
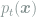
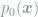
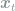
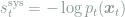

In order to express other ensemble-averaged quantities, we introduce the probability current,

such that we can write the equation of motion for the probability density, known as the Fokker-Planck equation, as,

Using this we can show that the entropy produced in the environment is,

and we find the total entropy production to be nonnegative, as required by the second law,
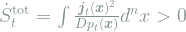
Thermodynamics and learning
The perceptron is a linear classifier that maps a vector of 

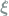
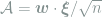
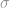
Here we follow Goldt & Seifert (2017),[efn_note]Goldt, S., & Seifert, U. (2017). Thermodynamic efficiency of learning a rule in neural networks. New Journal of Physics, 19(11), 113001. https://doi.org/10.1088/1367-2630/aa89ff[/efn_note] and consider a situation where there is a predefined weight vector 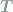


Here, 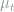

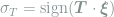


We consider forces of the form
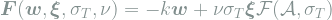
To a physicist, the first term represents a conservative force that drives the weights towards the minimum of a potential energy 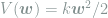
The input-dependent force drives the weight vector in the direction of alignment (when 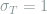
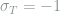
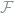
| Learning rule |  |
| Hebbian |  |
| Perceptron | 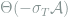 |
| AdaTron | 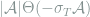 |
 -tron -tron |  |
Here, 
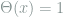

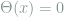

To fully specify the problem, we must define two sets of inputs: a training set 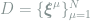


As the performance metric for training we will use the generalization error 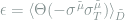

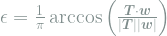
The generalization error can be related to the mutual information between the predicted and correct label: 
Steady state entropy production of learning
For the learning to converge to a steady state, we will assume a separation of timescales between the process
In steady state, the system entropy is constant and the prevailing entropy production must occur in the environment. Hence, we can write the total steady-state entropy production as,
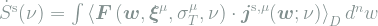
Here we write 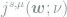

The steady-state currents can be written in terms of the force and steady-state probability density 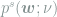
![\boldsymbol{j}^{\text{s},\mu} (\boldsymbol{w}; \nu) = \left[\boldsymbol{F} \left(\boldsymbol{w}, \boldsymbol{\xi}^\mu, \sigma_T^\mu, \nu\right) - \nabla \right] p^\text{s} (\boldsymbol{w}; \nu)](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7Bj%7D%5E%7B%5Ctext%7Bs%7D%2C%5Cmu%7D+%28%5Cboldsymbol%7Bw%7D%3B+%5Cnu%29+%3D+%5Cleft%5B%5Cboldsymbol%7BF%7D+%5Cleft%28%5Cboldsymbol%7Bw%7D%2C+%5Cboldsymbol%7B%5Cxi%7D%5E%5Cmu%2C+%5Csigma_T%5E%5Cmu%2C+%5Cnu%5Cright%29+-+%5Cnabla+%5Cright%5D+p%5E%5Ctext%7Bs%7D+%28%5Cboldsymbol%7Bw%7D%3B+%5Cnu%29+&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
and by subtracting the input-averaged version of the same equation we find that,
![\boldsymbol{j}^{\text{s},\mu}(\boldsymbol{w}; \nu) = \left\langle \boldsymbol{j}^{\text{s},\mu}(\boldsymbol{w}; \nu) \right\rangle_D + p^\text{s}(\boldsymbol{w}; \nu) \left[\boldsymbol{F}(\boldsymbol{w}, \boldsymbol{\xi}^\mu, \sigma_T^\mu, \nu) - \left\langle \boldsymbol{F}(\boldsymbol{w}, \boldsymbol{\xi}^\mu, \sigma_T^\mu, \nu) \right\rangle_D\right]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7Bj%7D%5E%7B%5Ctext%7Bs%7D%2C%5Cmu%7D%28%5Cboldsymbol%7Bw%7D%3B+%5Cnu%29+%3D+%5Cleft%5Clangle+%5Cboldsymbol%7Bj%7D%5E%7B%5Ctext%7Bs%7D%2C%5Cmu%7D%28%5Cboldsymbol%7Bw%7D%3B+%5Cnu%29+%5Cright%5Crangle_D+%2B+p%5E%5Ctext%7Bs%7D%28%5Cboldsymbol%7Bw%7D%3B+%5Cnu%29+%5Cleft%5B%5Cboldsymbol%7BF%7D%28%5Cboldsymbol%7Bw%7D%2C+%5Cboldsymbol%7B%5Cxi%7D%5E%5Cmu%2C+%5Csigma_T%5E%5Cmu%2C+%5Cnu%29+-+%5Cleft%5Clangle+%5Cboldsymbol%7BF%7D%28%5Cboldsymbol%7Bw%7D%2C+%5Cboldsymbol%7B%5Cxi%7D%5E%5Cmu%2C+%5Csigma_T%5E%5Cmu%2C+%5Cnu%29+%5Cright%5Crangle_D%5Cright%5D+&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
Plugging this back into the expression for total entropy production, we obtain two distinct terms, and write 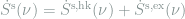

which is the entropy production required to maintain the steady state. This contribution would remain the same in a batch learning scenario where the force does not fluctuate from scanning through training examples, but instead takes the average value 
The fluctuations are responsible for the second contribution, the excess entropy production,
![\dot{S}^{\text{s},\text{ex}}(\nu) = N \nu^2 \int p^\text{s}(\boldsymbol{w}; \nu) \left[ \left\langle \mathcal{F} \left(\mathcal{A}^\mu, \sigma_T^\mu \right)^2 \right\rangle_D - \left\langle \mathcal{F} \left(\mathcal{A}^\mu, \sigma_T^\mu \right) \right\rangle_D^2 \right] d^n w](https://s0.wp.com/latex.php?latex=%5Cdot%7BS%7D%5E%7B%5Ctext%7Bs%7D%2C%5Ctext%7Bex%7D%7D%28%5Cnu%29+%3D+N+%5Cnu%5E2+%5Cint+p%5E%5Ctext%7Bs%7D%28%5Cboldsymbol%7Bw%7D%3B+%5Cnu%29+%5Cleft%5B+%5Cleft%5Clangle+%5Cmathcal%7BF%7D+%5Cleft%28%5Cmathcal%7BA%7D%5E%5Cmu%2C+%5Csigma_T%5E%5Cmu+%5Cright%29%5E2+%5Cright%5Crangle_D+-+%5Cleft%5Clangle+%5Cmathcal%7BF%7D+%5Cleft%28%5Cmathcal%7BA%7D%5E%5Cmu%2C+%5Csigma_T%5E%5Cmu+%5Cright%29+%5Cright%5Crangle_D%5E2+%5Cright%5D+d%5En+w+&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
where we simplified the expression by substituting the definition of 
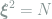
One of the main contributions of this work is identifying the latter term, a contribution to the excess entropy production that remains even in the steady state. In Goldt & Seifert (2017), the assumption of time scale separation was taken to imply that there would be no difference between presenting inputs sequentially (online learning) and in batch, and this effect of fluctuations was therefore neglected. A question not pursued here is whether this refinement modifies any of the bounds on mutual information from their paper.
Learning by adaptation?
How do we choose a good learning rule 
It has been observed that in many complex systems out of equilibrium, the likelihood of observing a particular outcome grows with the amount of heat dissipated over the history leading up to that outcome. The hypothesis of dissipative adaptation asserts that, as a corollary of this, one should expect many complex systems to evolve towards regions of state space where they absorb a lot of work from their driving forces so they can dissipate a lot of heat to their environments.[efn_note]Perunov, N., Marsland, R. A., & England, J. L. (2016). Statistical Physics of Adaptation. Physical Review X, 6(2), 021036. https://doi.org/10.1103/PhysRevX.6.021036[/efn_note] For example, simulations have demonstrated a tendency for many-species chemical reaction networks to evolve towards statistically exceptional configurations that are uniquely adapted to absorbing work from the external drives they are subjected to.[efn_note]Horowitz, J. M., & England, J. L. (2017). Spontaneous fine-tuning to environment in many-species chemical reaction networks. Proceedings of the National Academy of Sciences of the United States of America, 114(29), 7565–7570. https://doi.org/10.1073/pnas.1700617114[/efn_note] Inspired by this, we want to investigate the performance of learning rules designed such that the force fluctuations increase as the generalization error decreases. The
A simulation
Now that we begin to understand the thermodynamical perspective on learning and the (admittedly quite speculative) rationale behind the 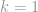


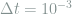

Among the three established algorithms, we see that Hebbian learning is the clear winner. Interestingly, however, the 
Probably not. First of all, this simulation is a little bit of a bodge. We sample training examples at random at each time step, but a step size of 



A methodological problem is of course that this is just a single run at a single point in parameter space. More thorough studies are needed before interesting claims can be made.
More importantly, we have not actually looked at the rate of entropy production after convergence, so we cannot say whether the solid 
Finally, we have not said much about an essential aspect of the systems for which dissipative adaptation is relevant, namely that they are complex. Sophisticated machine learning algorithms such as deep convolutional neural networks with nonlinearities in every layer are arguably quite complex, and biological systems that can learn or adapt, such as brains, immune systems, gene regulatory networks, ecological networks, and so on, are some the most complex systems known. It is for such systems that dissipative adaptation can emerge because strong fluctuations can help the system overcome energy barriers that would otherwise confine it to a small region of its state space. The perceptron, on the other hand, is not a complex system at all; it is a simple tug-of-war between a learning force that fluctuates a little but always points in the same general direction, a deterministic regularization force derived from a quadratic potential, and, in our version, some thermal noise sprinkled on top. Moreover, in certain limiting cases, the mean learning force is a simple function of
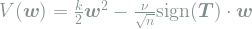
where the sign function applies elementwise. Hebbian learning in the perceptron is thus little more than thermal equilibration in a quadratic potential—the simplest system imaginable!
All this is to say that one should probably not expect dissipative adaptation to be a viable learning mechanism in the perceptron, even though the
Outreach
For the EE 376A outreach event, rather than discussing perceptrons and thermodynamics with elementary school children I wanted to convey the idea of complex systems that respond to external forcing by adopting far-from-equilibrium states where weird things happen. The obvious choice was to demonstrate corn starch and water!
A suspension of corn starch in water in the right proportions (about 5/8 corn starch) forms a strongly shear-thickening fluid, which runs like a liquid when left to itself but acts as a solid as soon as a force is applied. This is cool already, but the real fun happens when subjecting the mixture to strong vibrations. Take a look at this video, recorded at the outreach event:
When the vibrations are at their strongest, the puddle almost seems to morph into a primitive life form. The suspension exhibits strongly nonlinear interactions that respond to the external forcing in a very unpredictable manner, and the net effect is the dancing and crawling we see in the video. Even without a detailed understanding of flocculation at the microscopic level, it is clear that the vibrations push the suspension very far away from equilibrium and into highly dissipative states that must absorb a lot of energy from the speaker to persist. In other words, it might not unreasonable to interpret this as a simple example of dissipative adaptation: the suspension, being a complex system, responds to the forcing from the speaker by finding a corner in state space where the amount of energy absorbed from the speaker as work and dissipated to the environment as heat is unusually high.
My spiel to the kids was that the fluid is a thrill seeker and wants to get the biggest buzz it can out of the vibrating speaker, so what can it do but learn the rhythm and start dancing? In the same way, our brain wants to get the biggest buzz it can out of the signals it receives through our senses, so it has to pay attention, figure out common patterns, and play along—and that is what we call learning!
To the extent the last statement carries any substance, it is also just speculative conjecture. For anyone wanting to find out more, thermodynamics provides one possible link between the complex dynamics of brains in a noisy environment and the information measures that are the natural currency of a learning system.
Model Free Learning of Channel Codes forContinuous and Discrete Additive Channels
EE376A (Winter 2019)With the growth of digital communication, achieving the full capability of communication channels grows even more crucial. Modern error correcting codes such as LDPC and Turbo codes provide schemes that help achieve high efficiency over theoretical communication channels, but using them in practice often does not acheive the theoretical results because real-world channels do not have easily describable noise models. Using deep neural network based autoencoders, we present a method for constructing codes even when it is not possible to create an accurate noise model for the channel. To achieve this on discrete channels, which present challenges for deep learning, we combine a channel relaxation scheme to allow for training and a dithered quantization scheme to improve results significantly.
Outreach
For the outreach event, we demonstrated a simplified version of the problem we aimed to solve with our project. Elementary schoolers were presented with a challenge to “solve” or “decode” an unknown communication channel. In particular, we asked them to send a word over a simulated channel from one computer to another. Prizes were awarded to students who could send a message from one side to the other and have it show a target message (“banana” or “strawberry”) as the corrupted message on the other screen. Because they didn’t know how the channel worked at first, this required some trial and error to see how the channel was corrupting the input. (For simplicity, our channel was one-to-one.) This is an analogue of the machine learning task we tackled, which used Monte Carlo sampling of unknown channels as one step in learning deep autoencoders to communicate reliably over those channels.

The channel simulation was implemented as a server in Node JS and physically demonstrated by presenting two computers to the students. Each was connected to the server in Chrome and displayed a webpage with “send message” and “received message” fields. We originally had three options for how the channel would corrupt the codewords, but we settled on using one that simply reversed the codeword for most of the demonstrations, as it was the only one that students could consistently “solve”. We’d consider our demo to be a success!
Emergence of compositional sequential codes among RL agents
EE376A (Winter 2019)Govardana Sachithanadam Ramachandran
Abstract
Communication in living things arise out of necessity. Animals associate each sound they make to an intent, for example dogs bark could mean one of few intents such as warning, intimidation, mating call etc.,. But human languages are compositional, with fewer than 5000 words one could describe anything from cardiac surgery to Hamlet of Shakespeare. Compositional rich language have high information capacity and generalize to unseen scenarios, an example would be kids making up new words by morphologically associating known words. This project analyzes and find ways to encourage the emergence of these compositional language –which be can interpreted as source coding of intents– in a simulated multi AI agent Reinforcement Learning population. In this work we process optimization schemes to train a neural network for discrete sequential code communication among RL agents
Full report can be found here
Outreach
It was quite challenging and gratifying to explaine my project to the students of Nixon Elementary School. I was faced with the challenge of explaining concepts from Information theory and reinforcement learning. I tried to distill the core concepts with ample use of visual aid, cartoon characters and videos, which the kids could relate to .
One example, is explaining the fact that human language have higher information capacity compared to their animal counterpart. For which I played various sounds a fox makes and their corresponding intent
For the compositionality of human language, I encouraged them to come up new sentence by rearranging words, with below sentences as example

Another example, is explaining the concept of training a reinforcement learning model. For this I gave the analogy of training a dog to do tricks, explaining the concept of reinforcing behavior with rewards in the form of treats


Overall it was fun. One key take away is that, it was easier to get the concept to across if I engaged their parents as part of the presentation, as they were able to abstract the concept even further so that the kids could understand