Karan Singhal and Neel Yerneni
Most people are first introduced to the ideas of information theory through puzzles and games. We encountered 20 Questions and coin weighing well before entropy and joint source-channel encoding. Given the popularity of puzzles and games backed by information theoretic concepts, studying these puzzles can provide insight into how the general public views information theory and how information theoretic concepts can be communicated to a broader audience.
We discuss seven puzzles involving information theoretic concepts, four of which we created for the outreach event at Nixon Elementary School. We propose a simple taxonomy for these puzzles that reflects the fundamental concepts involved in each. While this taxonomy is not exhaustive, we hope it proves useful in demonstrating that these puzzles often have shared foundations in information theory.
Bits Encode Possibilities
As information theorists, we know that a small number of bits can be used to express one of exponentially many possibilities. This principle is used in games where one player is able to “read the mind” of another player, determining which of many possibilities the other player is thinking of despite receiving a seemingly paltry amount of information.

The most well-known of this category of games is 20 Questions, which was popularized by the 20Q handheld toy owned by many children during the 2000’s. In this game, the user is challenged to think of anything or anyone she wants–an actor, a board game, a fictional character, a national monument, etc. The toy asks a series of 20 yes/no/sometimes/unknown questions about the thing the user is thinking of (e.g., is the thing a person?). At some point when it becomes more confident, the toy begins guessing specific things that the user might be thinking of. If the toy cannot guess the thing after a number of guesses, the user wins. As owners of the original toy know, the toy was able to guess the thing that the user is thinking of–no matter what it was–almost every time. A modified adaptive version of the game, where questions can have more than four possible answers, can be found online.
Armed with the tools of information theory, we can begin to deconstruct the success of the toy. The toy must have a fixed list of possible things (roughly 2^20 = 1,000,000 things) that the user might think of (since it was not connected to the internet), and it must choose its questions so that the number of possibilities is split in roughly half each time to minimize the number of questions it asks. For example, if half the possibilities that the toy is still considering at some stage of the game are humans and the other half are not, the toy would do well to ask: Is it human? This says nothing about how to choose such a question efficiently, especially since people will provide unpredictable answers to ambiguous questions (e.g., is a fictional humanoid alien character a person or not?). Even in cases like this, the toy was expected to guess the thing correctly (and it usually did!). It turns out that the toy, whose algorithm was first developed in 1988 as a test of artificial intelligence, is actually powered by an artificial neural network that figures out which questions to ask and guesses to make. Though most probably did not realize it, for many children growing up in the 2000’s, this toy might have been their first exposure to ideas from both information theory and artificial intelligence! Unfortunately, the original toy was discontinued in 2011 due to licensing issues.
We were inspired by the success of this toy in presenting information theory concepts to the broadest possible audience, so we created our own simple game to evoke the same wonder in today’s elementary school students: 1000 Numbers. We asked students to think of a number from 1 to 1000 (inclusive) and told them we could guess it using ten guesses, as long as they told us whether our guess was correct, too high, or too low. If we could not get it within ten guesses, students won candy. We then performed binary search in real-time, guessing the number within ten guesses. It turns out that only ten guesses are needed, no matter which number a student chooses, even though 1000 < 2^10 = 1024. We show this in a simple Python simulation. This is because each guess actually provides more than a bit of information–we know whether our guess was too high or too low, but we also know whether it is correct or not, which is especially useful when the number of possibilities left to consider is low.
We found that 1000 Numbers was our most popular puzzle on the day of the outreach. Students of all ages were surprised and delighted to find that we could guess their number using few guesses (an average of eight guesses, according to our simulation). Even though we could always guess their number within ten guesses (unless we made an error during the mental math associated with binary search in real-time), we provided candy to all students who participated.
Decisions Create Information
Puzzles often ask people to make informative decisions. In an uncertain situation, making the right decision can reveal crucial information. This is best illustrated by example; consider the popular genre of puzzles involving weighing coins.
The canonical version of this puzzle is as follows. You have nine coins in front of you. All of them are identical except for one counterfeit coin, which is lighter than the other eight. If you have a balance that can compare the weights of any subset the coins with another subset, at most how many weighings would it take to figure out which of the coins is counterfeit?
Observe that each weighing can provide a variable amount of information, depending on the choice of coins to weigh. For example, if two random coins are weighed against each other for the first weighing, this does not seem very informative (in the worst case), since it is likely that we will be left with seven possible counterfeit coins after the weighing. Compare this to weighing two sets of three coins, which is part of the optimal solution and allows us to narrow the possible counterfeit coins to three in both the best and worst case. Thus, making the right decision can create important information.
In the canonical problem presented above, it turns out that just two weighings are needed. In the first weighing, some three coins are compared to some other three coins. Based on the result of this weighing, we can narrow down the possibilities to three. We then weigh any two of these. If one of these is lighter, then we have our desired counterfeit coin. If neither is lighted, then the third unweighed coin must be the counterfeit coin. This solution is illustrated below.

Note that with each weighing we can reduce the number of possibilities by a factor of three using the optimal weighing, so the problem reduces to encoding nine possibilities in ternary, which can be done using two digits (corresponding to two weighings). Thus, if 27 coins were present instead, three weighings would be sufficient. Many other variations of this puzzle build off this information theoretic foundation.
Another example of a puzzle in which decisions create information is presented in Quanta’s puzzle column from July 2015. In this puzzle, you seem to be able to win a number-guessing game without any information.
The puzzle is presented as follows:
I write down two different numbers that are completely unknown to you, and hold one in my left hand and one in my right. You have absolutely no idea how I generated these two numbers. Which is larger? You can point to one of my hands, and I will show you the number in it. Then you can decide to either select the number you have seen or switch to the number you have not seen, held in the other hand, as your final choice. Is there a strategy that will give you a greater than 50 percent chance of choosing the larger number, no matter which two numbers I write down?
Pradeep Mutalik, Quanta Puzzle Columnist
When faced with this puzzle, most readers are likely to rely on concrete assumptions over the distribution from which numbers are drawn (e.g., people are likely to choose a number from 1 to 1000). It turns out this kind of assumption is not necessary.
The solution provided by the column is to pick a random number G before pointing to one of the hands. If the revealed number is larger than G, select the revealed number. If it is smaller, switch. The column provides a detailed discussion of this strategy and why it yields a greater than 50% chance of choosing the larger number (even if numbers are chosen over an infinite space), but the intuition is that in most cases, whether you stay or switch, your conditional probability of winning is still 50%. In one case, however, where one of the numbers is less than G and the other is greater, then you are guaranteed to win by playing your strategy. Then as long as you assume that there is a nonzero chance of your random number being in between the two numbers (a mild assumption), this strategy has a greater than 50% chance of choosing the larger number.
In this puzzle, as before, being strategic about how to act in a constrained environment introduces information.
Channels Are Noisy
Channels transmitting information are not always able to transmit exactly what was originally intended–there is often noise. Languages evolved as people needed to be able to communicate given the chance that there might be noise in transmission. The redundancy of modern language has rendered many problems related to noisy channels obsolete in practical situations. This allows people to infer correct meaning even with noise in the transmission.
To conceptualize this as an activity, we wanted to explore scenarios within the English language where original words in a cohesive text could be inferred despite the redaction of certain letters. In the outreach activity, we introduced two games that built on this. The first was Reconstructing Text. We randomly replaced certain letters in a piece of text and had the student reconstruct the text to the best of their ability. With this game, we noticed that students had little trouble reconstructing the text correctly as they were able to infer what the missing words were. We noticed that most of the words that students got incorrect were ones where most of the consonants were replaced by noise rather than the vowels. This made sense as consonants often carry more information than vowels in English words, which we hoped to convey to the students.
The second game we made was the Text Message Game. For this game, students worked in pairs. One student was responsible for masking the letters and the other was to guess the letters that were blacked out. Though this game was less popular due to its complexity, we thought it gave students an even stronger glimpse into the limits and nuances of the redundancies of language as they were encouraged to black out as many letters as they could but so long as their partner could perfectly reconstruct it. This activity provided a much more hands-on exploration as students also had to directly consider the implications behind the transmission of their information.
Coding
The encoding of information is another critical concept in the field of information theory and tends to be more complex. In constructing an activity surrounding this concept, we wanted to obviate some of the more involved notions and convey more abstract, generalized concepts in the encoding of information. Specifically, we wanted to explore the idea that smaller symbols could be combined in different ways to communicate more complex concepts.
In our activity at the outreach event, we had students pair up where one student was blindfolded and the other student needed to give the first instructions to complete a maze. However, to do so, the instructing student could only use three pre-outlined words (we used soy, sugar, and glue in our activity), even though there were four possible directions for movement in the maze. It was then up to the students to come up with a plan for how they wanted to convey the proper instructions via these three words beforehand.
We were surprised by the diversity in methods taken by students to use these three words to instruct their partner. While some students worked in the dimension of the words themselves (i.e., using permutations of the words to convey more complex instructions), others made use of other dimensions of variation. One example was a group of students who decided to alter their pitch in saying the word as a mechanism for signaling the direction of movement. We did not expect this solution!
Conclusion
We have proposed a simple taxonomy for seven puzzles involving information theoretic concepts, some of our own creation. Besides furthering our understanding of how these puzzles relate, our analysis may also prove useful in producing curriculum introducing students to information theory. The outreach event is highly relevant: in our station, we presented four puzzles (1000 Numbers, Reconstructing Text, Text Message Game, and Soy-Sugar-Glue) using worksheets that students could take home with them, along with copious prizes (candy) for students who were able to complete the puzzles. We found that students were generally quite excited to complete the puzzles both individually and in pairs, indicating that these and other puzzles could serve as excellent teaching tools for the popularization of information theory.
Our full worksheets that we created for the outreach event: 1000 Numbers, Reconstructing Text, Text Message Game, and Soy-Sugar-Glue.
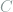 , which takes in a messages
, which takes in a messages  of length
of length 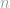 , with each
, with each 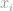 taking values in an alphabet of size
taking values in an alphabet of size 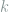 .
.  of size
of size  , so the output is
, so the output is  , where
, where  are the indices which are not deleted by
are the indices which are not deleted by  is, then you can again use
is, then you can again use 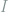 and putting arbitrary symbols in
and putting arbitrary symbols in 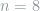 ,
,  , and
, and 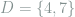 .
. 
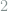 . The deletion indices are
. The deletion indices are 

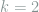 . Our first observation is that that given a set of codewords to send through the channel, we can model the problem of identifying the deletion indices as solving linear system.
. Our first observation is that that given a set of codewords to send through the channel, we can model the problem of identifying the deletion indices as solving linear system.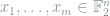 be the
be the 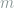 codewords we will send through the channel. We then let
codewords we will send through the channel. We then let 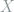 be the the matrix whose columns are these codewords, that is,
be the the matrix whose columns are these codewords, that is,
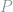 , which, when multiplied by a codeword
, which, when multiplied by a codeword  , yields the result of passing
, yields the result of passing  through the channel,
through the channel, 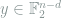 . We do this by letting $P$ be a submatrix of the
. We do this by letting $P$ be a submatrix of the 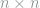 identity matrix. In particular, if
identity matrix. In particular, if 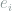 be the one-hot vector in the
be the one-hot vector in the 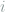 -th coordinate, let
-th coordinate, let  in ascending order. For example, if
in ascending order. For example, if 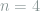 and
and 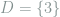 , then
, then
 , with our newly defined matrices
, with our newly defined matrices 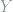 is the matrix whose columns are the results of passing the columns of
is the matrix whose columns are the results of passing the columns of  . In particular, we let
. In particular, we let 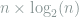 matrix whose rows are all the binary of length
matrix whose rows are all the binary of length  from binary strings of length eight. Then, the matrix
from binary strings of length eight. Then, the matrix 

 is
is 
 , which tells us precisely that
, which tells us precisely that 














