(Warning: These materials may be subject to lots of typos and errors. We are grateful if you could spot errors and leave suggestions in the comments, or contact the author at yjhan@stanford.edu.)
In the last lecture we introduced Le Cam’s two-point method to establish information-theoretic lower bounds, where the target is to find two single hypotheses which are well separated while indistinguishable. However, restricting to two single hypotheses gives the learner a lot of information in many scenarios, and any pair of single hypotheses which are far apart becomes distinguishable. From another point of view, if we would like to mimic the Bayesian idea of using the least favorable prior, it is very unlikely that the least favorable prior is supported on only two points. Hence, in this lecture we generalize the two-point idea to the case where one point is a mixture of distributions, which suits well in various examples.
1. General Tools
1.1. A Motivating Example
We first discuss an example where the simple two-point method fails. Consider the following hidden clique detection problem: there is an underlying undirected simple graph 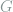
![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
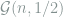

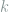
This task is a composite hypothesis testing problem, where 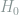

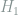
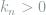
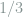

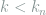
We first try to use Le Cam’s two-point method to find a lower bound on 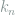


![S\subseteq [n]](https://s0.wp.com/latex.php?latex=S%5Csubseteq+%5Bn%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)

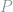
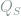

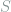
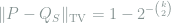
holds for any 

The problem with the above two-point approach is that, if the learner is told the exact location of the clique, she can simply look at the subgraph supported on that location and tell whether a clique is present. In other words, any single hypothesis from
1.2. Generalized Le Cam’s Method: Point vs. Mixture
As is shown in the previous example, there is need to generalize the Le Cam’s two-point method to the scenario where one of the points is a mixture of distributions. The theoretical foundation of the generalization is in fact quite simple, and the proof of the next theorem parallels that of Theorem 7 in Lecture 5.
Theorem 1 (Point vs. Mixture) Let
be any loss function, and there exist
and
such that
then for any probability measure
supported on
, we have

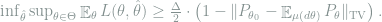
The main difficulties in the practical application of Theorem 1 lie in two aspects. First, it may be non-trivial to find the proper mixture 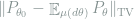


1.3. Upper Bounding the Divergence
To upper bound the divergence between a single distribution and a mixture of distributions, the next lemma shows that the 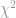
Lemma 2 Let
be a family of probability distributions parametrized by
, and
be any fixed probability distribution. Then for any probability measure
, we have
where the expectation is taken with respect to independent
.
![\chi^2\left(\mathop{\mathbb E}_\mu [P_\theta], Q \right) = \mathop{\mathbb E}\left[ \int \frac{dP_\theta dP_{\theta'}}{dQ} \right] - 1,](https://s0.wp.com/latex.php?latex=+%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_%5Cmu+%5BP_%5Ctheta%5D%2C+Q+%5Cright%29+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Cint+%5Cfrac%7BdP_%5Ctheta+dP_%7B%5Ctheta%27%7D%7D%7BdQ%7D+%5Cright%5D+-+1%2C+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
Proof: Follows from the definition 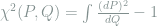

The advantages of Lemma 2 are two-fold. First, it factorizes well for tensor products:
![\chi^2\left(\mathop{\mathbb E}_\mu [P_\theta^{\otimes n}], Q^{\otimes n} \right) =\mathop{\mathbb E}\left[ \left( \int \frac{dP_\theta dP_{\theta'}}{dQ}\right)^n \right] - 1.](https://s0.wp.com/latex.php?latex=+%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_%5Cmu+%5BP_%5Ctheta%5E%7B%5Cotimes+n%7D%5D%2C+Q%5E%7B%5Cotimes+n%7D+%5Cright%29+%3D%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Cleft%28+%5Cint+%5Cfrac%7BdP_%5Ctheta+dP_%7B%5Ctheta%27%7D%7D%7BdQ%7D%5Cright%29%5En+%5Cright%5D+-+1.+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
This identity makes it more convenient to use
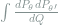
admits a simple closed-form expression in 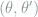
2. Examples of Testing Problems
In this section, we provide examples of composite hypothesis testing problems where the null hypothesis
2.1. Hidden Clique Detection
Recall the hidden clique detection problem described in Section 1.1, where we aim to obtain tight lower bounds for the threshold ![\mathop{\mathbb E}_S[Q_S]](https://s0.wp.com/latex.php?latex=%5Cmathop%7B%5Cmathbb+E%7D_S%5BQ_S%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
![\chi^2(\mathop{\mathbb E}_S[Q_S], P)](https://s0.wp.com/latex.php?latex=%5Cchi%5E2%28%5Cmathop%7B%5Cmathbb+E%7D_S%5BQ_S%5D%2C+P%29&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
![\chi^2(\mathop{\mathbb E}_S[Q_S], P) = \mathop{\mathbb E}_{S,S'}\left[ \int \frac{dQ_S dQ_{S'}}{dP} \right] - 1.](https://s0.wp.com/latex.php?latex=+%5Cchi%5E2%28%5Cmathop%7B%5Cmathbb+E%7D_S%5BQ_S%5D%2C+P%29+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7BS%2CS%27%7D%5Cleft%5B+%5Cint+%5Cfrac%7BdQ_S+dQ_%7BS%27%7D%7D%7BdP%7D+%5Cright%5D+-+1.+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
By simple algebra,

Since the probability of 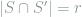
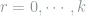

![\begin{array}{rcl} \chi^2(\mathop{\mathbb E}_S[Q_S], P) = \sum_{r=0}^k 2^{\binom{r}{2}}\cdot \frac{\binom{k}{r} \binom{n-k}{k-r}}{\binom{n}{k}} - 1 = \sum_{r=1}^k 2^{\binom{r}{2}}\cdot \frac{\binom{k}{r} \binom{n-k}{k-r}}{\binom{n}{k}} . \end{array}](https://s0.wp.com/latex.php?latex=+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cchi%5E2%28%5Cmathop%7B%5Cmathbb+E%7D_S%5BQ_S%5D%2C+P%29+%3D+%5Csum_%7Br%3D0%7D%5Ek+2%5E%7B%5Cbinom%7Br%7D%7B2%7D%7D%5Ccdot+%5Cfrac%7B%5Cbinom%7Bk%7D%7Br%7D+%5Cbinom%7Bn-k%7D%7Bk-r%7D%7D%7B%5Cbinom%7Bn%7D%7Bk%7D%7D+-+1+%3D+%5Csum_%7Br%3D1%7D%5Ek+2%5E%7B%5Cbinom%7Br%7D%7B2%7D%7D%5Ccdot+%5Cfrac%7B%5Cbinom%7Bk%7D%7Br%7D+%5Cbinom%7Bn-k%7D%7Bk-r%7D%7D%7B%5Cbinom%7Bn%7D%7Bk%7D%7D+.+%5Cend%7Barray%7D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
After carefully bounding the binomial coefficients, we conclude that the 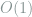

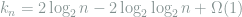
This lower bound is tight. Note that the expected number of size-

using some algebra and Markov’s inequality, we conclude that if 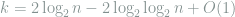
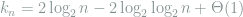
2.2. Uniformity Testing
The uniformity testing problem, also known as the goodness-of-fit in theoretical computer science, is as follows. Given 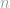

where 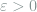
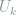
![[k]](https://s0.wp.com/latex.php?latex=%5Bk%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
Note that 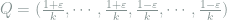

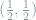



Hence, we should pick up several distributions from 
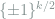
![\mathop{\mathbb E}_v[Q_v^{\otimes n}]](https://s0.wp.com/latex.php?latex=%5Cmathop%7B%5Cmathbb+E%7D_v%5BQ_v%5E%7B%5Cotimes+n%7D%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
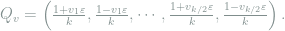
Clearly, each 
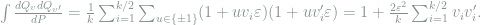
Therefore, by Lemma 2 and the discussions thereafter, we have
![\begin{array}{rcl} \chi^2\left(\mathop{\mathbb E}_v[Q_v^{\otimes n}], P^{\otimes n} \right) +1 &=& \mathop{\mathbb E}_{v,v'}\left[ \left(1 + \frac{2\varepsilon^2}{k}\sum_{i=1}^{k/2} v_iv_i'\right)^n \right] \\ &\le & \mathop{\mathbb E}_{v,v'} \exp\left(\frac{2n\varepsilon^2}{k} \sum_{i=1}^{k/2} v_iv_i' \right) \\ &\le & \mathop{\mathbb E}_v \exp\left(\frac{2n^2\varepsilon^4}{k^2} \|v\|_2^2 \right) \\ &=& \exp\left(\frac{n^2\varepsilon^4}{k} \right), \end{array}](https://s0.wp.com/latex.php?latex=+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_v%5BQ_v%5E%7B%5Cotimes+n%7D%5D%2C+P%5E%7B%5Cotimes+n%7D+%5Cright%29+%2B1+%26%3D%26+%5Cmathop%7B%5Cmathbb+E%7D_%7Bv%2Cv%27%7D%5Cleft%5B+%5Cleft%281+%2B+%5Cfrac%7B2%5Cvarepsilon%5E2%7D%7Bk%7D%5Csum_%7Bi%3D1%7D%5E%7Bk%2F2%7D+v_iv_i%27%5Cright%29%5En+%5Cright%5D+%5C%5C+%26%5Cle+%26+%5Cmathop%7B%5Cmathbb+E%7D_%7Bv%2Cv%27%7D+%5Cexp%5Cleft%28%5Cfrac%7B2n%5Cvarepsilon%5E2%7D%7Bk%7D+%5Csum_%7Bi%3D1%7D%5E%7Bk%2F2%7D+v_iv_i%27+%5Cright%29+%5C%5C+%26%5Cle+%26+%5Cmathop%7B%5Cmathbb+E%7D_v+%5Cexp%5Cleft%28%5Cfrac%7B2n%5E2%5Cvarepsilon%5E4%7D%7Bk%5E2%7D+%5C%7Cv%5C%7C_2%5E2+%5Cright%29+%5C%5C+%26%3D%26+%5Cexp%5Cleft%28%5Cfrac%7Bn%5E2%5Cvarepsilon%5E4%7D%7Bk%7D+%5Cright%29%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
where the last inequality follows from the 



2.3. General Identity Testing
Next we generalize the uniformity testing problem to the case where the uniform distribution 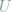

where 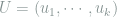

For simplicity, we assume that 


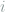

Here the parameters 



![\chi^2\left(\mathop{\mathbb E}_v[Q_v^{\otimes n}], P^{\otimes n} \right) +1 \le \mathop{\mathbb E}_{v,v'} \exp\left( 2n\sum_{i=1}^{k/2} \frac{\varepsilon_i^2}{u_i} v_iv_i' \right) \le \exp\left(2n^2\sum_{i=1}^{k/2} \frac{\varepsilon_i^4}{u_i^2} \right),](https://s0.wp.com/latex.php?latex=+%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_v%5BQ_v%5E%7B%5Cotimes+n%7D%5D%2C+P%5E%7B%5Cotimes+n%7D+%5Cright%29+%2B1+%5Cle+%5Cmathop%7B%5Cmathbb+E%7D_%7Bv%2Cv%27%7D+%5Cexp%5Cleft%28+2n%5Csum_%7Bi%3D1%7D%5E%7Bk%2F2%7D+%5Cfrac%7B%5Cvarepsilon_i%5E2%7D%7Bu_i%7D+v_iv_i%27+%5Cright%29+%5Cle+%5Cexp%5Cleft%282n%5E2%5Csum_%7Bi%3D1%7D%5E%7Bk%2F2%7D+%5Cfrac%7B%5Cvarepsilon_i%5E4%7D%7Bu_i%5E2%7D+%5Cright%29%2C+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
where again the last step follows from the sub-Gaussianity. Since our target is to find the largest possible 
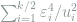
Lemma 3 (Hölder’s Inequality) Let
be non-negative reals for all
. Then

Proof: By homogeneity we may assume that 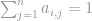
![i\in [m]](https://s0.wp.com/latex.php?latex=i%5Cin+%5Bm%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)

By Lemma 3, we have the following inequality:
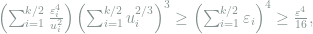
which gives the lower bound 

It is straightforward to check that
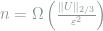
for the sample complexity, which is tight in general. Recall that how the mysterious 
3. Examples of Estimation Problems
In this section, we will look at several estimation problems and show how Theorem 1 provides the tight lower bound for these problems. We will see that the choice of the mixture becomes natural after we understand the problem.
3.1. Linear Functional Estimation of Sparse Gaussian Mean
Consider a Gaussian location model 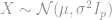


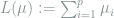

The key feature of this problem is the dependence of the minimax risk on the sparsity parameter 

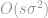


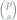
To incorporate the effect of unknown support into the lower bound, a natural choice would be to consider a random mean vector with support uniformly distributed on all size-![[p]](https://s0.wp.com/latex.php?latex=%5Bp%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
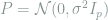

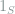
![S\subseteq [p]](https://s0.wp.com/latex.php?latex=S%5Csubseteq+%5Bp%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
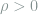


and consequently
![\chi^2\left(\mathop{\mathbb E}_S[Q_S], P \right) = \mathop{\mathbb E}_{S,S'} \exp\left(\frac{\rho^2}{\sigma^2} |S\cap S'|\right) - 1.](https://s0.wp.com/latex.php?latex=+%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_S%5BQ_S%5D%2C+P+%5Cright%29+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7BS%2CS%27%7D+%5Cexp%5Cleft%28%5Cfrac%7B%5Crho%5E2%7D%7B%5Csigma%5E2%7D+%7CS%5Ccap+S%27%7C%5Cright%29+-+1.+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
The random variable 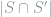
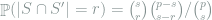

Lemma 4 Let
be an urn,
be samples uniformly drawn from the urn without replacement, and
be samples uniformly drawn from the urn with replacement. Define
and
, then there exists a coupling between
such that
.
Proof: The coupling is defined as follows: for any distinct 
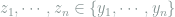
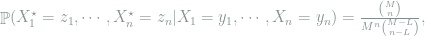
where 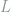


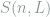
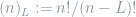
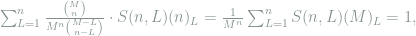
where the last step is due to that 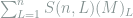

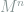
From this conditional probability, it is obvious to see that the unconditional probability of 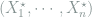
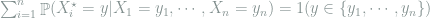
follows from symmetry, and therefore
By Lemma 4, there exists some 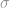

![\mathop{\mathbb E}[Z|\mathcal{B}]](https://s0.wp.com/latex.php?latex=%5Cmathop%7B%5Cmathbb+E%7D%5BZ%7C%5Cmathcal%7BB%7D%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)

![\chi^2\left(\mathop{\mathbb E}_S[Q_S], P \right) \le \mathop{\mathbb E} \exp(\rho^2 Z/\sigma^2 ) - 1 = \left(1 - \frac{s}{p} + \frac{s}{p}\exp(\rho^2/\sigma^2) \right)^s - 1.](https://s0.wp.com/latex.php?latex=+%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_S%5BQ_S%5D%2C+P+%5Cright%29+%5Cle+%5Cmathop%7B%5Cmathbb+E%7D+%5Cexp%28%5Crho%5E2+Z%2F%5Csigma%5E2+%29+-+1+%3D+%5Cleft%281+-+%5Cfrac%7Bs%7D%7Bp%7D+%2B+%5Cfrac%7Bs%7D%7Bp%7D%5Cexp%28%5Crho%5E2%2F%5Csigma%5E2%29+%5Cright%29%5Es+-+1.+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
Hence, the largest 


which has a phase transition at 
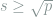
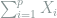
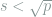


3.2. Largest Eigenvalue of Covariance Matrix
Consider i.i.d. observations 
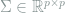

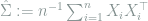

We show that the 

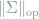
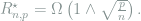
Note that by triangle inequality, estimating the largest eigenvalue is indeed an easier problem than covariance estimation.
As before, a natural idea to establish the lower bound is to choose a uniform direction for the principal eigenvector, so that the learner must distribute her effort into all directions evenly. Specifically, we choose 






Hence, by Lemma 2,
![\chi^2\left(\mathop{\mathbb E}_v[Q_v^{\otimes n}], P^{\otimes n}\right) +1 = \mathop{\mathbb E}_{v,v'} \left( 1 - \frac{b^2}{a^2}(v^\top v')^2 \right)^{-\frac{n}{2}} \le \mathop{\mathbb E}_{v,v'} \exp\left(\frac{nb^2}{a^2}(v^\top v')^2 \right)](https://s0.wp.com/latex.php?latex=+%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_v%5BQ_v%5E%7B%5Cotimes+n%7D%5D%2C+P%5E%7B%5Cotimes+n%7D%5Cright%29+%2B1+%3D+%5Cmathop%7B%5Cmathbb+E%7D_%7Bv%2Cv%27%7D+%5Cleft%28+1+-+%5Cfrac%7Bb%5E2%7D%7Ba%5E2%7D%28v%5E%5Ctop+v%27%29%5E2+%5Cright%29%5E%7B-%5Cfrac%7Bn%7D%7B2%7D%7D+%5Cle+%5Cmathop%7B%5Cmathbb+E%7D_%7Bv%2Cv%27%7D+%5Cexp%5Cleft%28%5Cfrac%7Bnb%5E2%7D%7Ba%5E2%7D%28v%5E%5Ctop+v%27%29%5E2+%5Cright%29+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
assuming 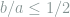


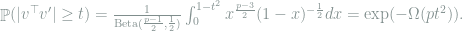
Consequently, to make ![\chi^2\left(\mathop{\mathbb E}_v[Q_v^{\otimes n}], P^{\otimes n}\right) = O(1)](https://s0.wp.com/latex.php?latex=%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_v%5BQ_v%5E%7B%5Cotimes+n%7D%5D%2C+P%5E%7B%5Cotimes+n%7D%5Cright%29+%3D+O%281%29&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
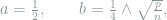
which gives the desired minimax lower bound 
3.3. Quadratic Functional Estimation
Finally we switch to a non-parametric example. Let 
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
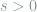
![f\in \mathcal{H}^s(L) := \left\{f\in C[0,1]: \sup_{x\neq y} \frac{|f^{(m)}(x) - f^{(m)}(y)| }{|x-y|^\alpha}\le L \right\},](https://s0.wp.com/latex.php?latex=+f%5Cin+%5Cmathcal%7BH%7D%5Es%28L%29+%3A%3D+%5Cleft%5C%7Bf%5Cin+C%5B0%2C1%5D%3A+%5Csup_%7Bx%5Cneq+y%7D+%5Cfrac%7B%7Cf%5E%7B%28m%29%7D%28x%29+-+f%5E%7B%28m%29%7D%28y%29%7C+%7D%7B%7Cx-y%7C%5E%5Calpha%7D%5Cle+L+%5Cright%5C%7D%2C+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
with ![s = m+\alpha, m\in \mathbb{N}, \alpha\in (0,1]](https://s0.wp.com/latex.php?latex=s+%3D+m%2B%5Calpha%2C+m%5Cin+%5Cmathbb%7BN%7D%2C+%5Calpha%5Cin+%280%2C1%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)

and we let 

which has an “elbow effect” at 
A central tool for proving nonparametric lower bounds is via parametric reduction, i.e., restricting
![f_v(x) = 1 + c_0L\cdot \sum_{i=1}^{h^{-1}/2} v_ih^s\left[ g\left(\frac{x-(2i-2)h}{h} \right) - g\left(\frac{x-(2i-1)h}{h} \right) \right],](https://s0.wp.com/latex.php?latex=+f_v%28x%29+%3D+1+%2B+c_0L%5Ccdot+%5Csum_%7Bi%3D1%7D%5E%7Bh%5E%7B-1%7D%2F2%7D+v_ih%5Es%5Cleft%5B+g%5Cleft%28%5Cfrac%7Bx-%282i-2%29h%7D%7Bh%7D+%5Cright%29+-+g%5Cleft%28%5Cfrac%7Bx-%282i-1%29h%7D%7Bh%7D+%5Cright%29+%5Cright%5D%2C+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
where 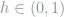

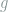

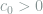



and therefore the target of the subproblem is to estimate 
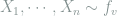
Let 
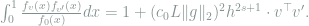
Consequently, Lemma 2 gives
![\begin{array}{rcl} \chi^2\left(\mathop{\mathbb E}_v[f_v^{\otimes n}], f_0^{\otimes n} \right) + 1 &=& \mathop{\mathbb E}_{v,v'} \left(1 + (c_0L\|g\|_2)^2h^{2s+1}\cdot v^\top v' \right)^n \\ &\le & \mathop{\mathbb E}_{v,v'} \exp\left( (c_0L\|g\|_2)^2nh^{2s+1}\cdot v^\top v'\right) \\ &\le& \exp\left(\frac{1}{2}(c_0L\|g\|_2)^4n^2h^{4s+2}\cdot \frac{1}{2h} \right). \end{array}](https://s0.wp.com/latex.php?latex=+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_v%5Bf_v%5E%7B%5Cotimes+n%7D%5D%2C+f_0%5E%7B%5Cotimes+n%7D+%5Cright%29+%2B+1+%26%3D%26+%5Cmathop%7B%5Cmathbb+E%7D_%7Bv%2Cv%27%7D+%5Cleft%281+%2B+%28c_0L%5C%7Cg%5C%7C_2%29%5E2h%5E%7B2s%2B1%7D%5Ccdot+v%5E%5Ctop+v%27+%5Cright%29%5En+%5C%5C+%26%5Cle+%26+%5Cmathop%7B%5Cmathbb+E%7D_%7Bv%2Cv%27%7D+%5Cexp%5Cleft%28+%28c_0L%5C%7Cg%5C%7C_2%29%5E2nh%5E%7B2s%2B1%7D%5Ccdot+v%5E%5Ctop+v%27%5Cright%29+%5C%5C+%26%5Cle%26+%5Cexp%5Cleft%28%5Cfrac%7B1%7D%7B2%7D%28c_0L%5C%7Cg%5C%7C_2%29%5E4n%5E2h%5E%7B4s%2B2%7D%5Ccdot+%5Cfrac%7B1%7D%7B2h%7D+%5Cright%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
Hence, choosing 
![\chi^2\left(\mathop{\mathbb E}_v[f_v^{\otimes n}], f_0^{\otimes n} \right) = O(1)](https://s0.wp.com/latex.php?latex=%5Cchi%5E2%5Cleft%28%5Cmathop%7B%5Cmathbb+E%7D_v%5Bf_v%5E%7B%5Cotimes+n%7D%5D%2C+f_0%5E%7B%5Cotimes+n%7D+%5Cright%29+%3D+O%281%29&bg=ffffff&fg=7f8d8c&s=0&c=20201002)


The parametric rate 
4. Bibliographic Notes
A wonderful book which treats the point-mixture idea of Theorem 1 sysmatically and contains the method in Lemma 2 is Ingster and Suslina (2012). The sharp bounds on the clique size in the hidden clique problem are due to Matula (1972). It is a long-standing open problem whether there exists a polynomial-time algorithm attaining this statistical limit, and we refer to the lecture notes Lugosi (2017) for details. The sample complexity of the uniformity testing problem is due to Paninski (2008), and the general identity testing problem is studied in Valiant and Valiant (2017). There are also some other generalizations or tools for uniformity testing, e.g., Diakonikolas and Kane (2016), Diakonikolas, Kane and Stewart (2018), Blais, Canonne and Gur (2019).
For the estimation problem, the linear functional estimation for sparse Gaussian mean is due to Collier, Comminges and Tsybakov (2017), where Lemma 4 can be found in Aldous (1985). The largest eigenvalue example is taken from the lecture note Wu (2017). The nonparametric functional estimation problem is widely studied in statistics, where the minimax rate for estimating the quadratic functional can be found in Bickel and Ritov (1988), and it is 

- Yuri Ingster and Irina A. Suslina. Nonparametric goodness-of-fit testing under Gaussian models. Vol. 169. Springer Science & Business Media, 2012.
- David W. Matula. Employee party problem. Notices of the American Mathematical Society. Vol. 19, No. 2, 1972.
- Gábor Lugosi. Lectures on Combinatorial Statistics. 2017.
- Liam Paninski. A coincidence-based test for uniformity given very sparsely sampled discrete data. IEEE Transactions on Information Theory 54.10 (2008): 4750–4755.
- Gregory Valiant and Paul Valiant. An automatic inequality prover and instance optimal identity testing. SIAM Journal on Computing 46.1 (2017): 429–455.
- Ilias Diakonikolas and Daniel M. Kane. A new approach for testing properties of discrete distributions. 2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS). IEEE, 2016.
- Ilias Diakonikolas, Daniel M. Kane, and Alistair Stewart. Sharp bounds for generalized uniformity testing. Advances in Neural Information Processing Systems. 2018.
- Eric Blais, Clément L. Canonne, and Tom Gur. Distribution testing lower bounds via reductions from communication complexity. ACM Transactions on Computation Theory (TOCT) 11.2 (2019): 6.
- Olivier Collier, Laëtitia Comminges, and Alexandre B. Tsybakov. Minimax estimation of linear and quadratic functionals on sparsity classes. The Annals of Statistics 45.3 (2017): 923–958.
- David J. Aldous. Exchangeability and related topics. Ecole d’Eté de Probabilités de Saint-Flour XIII-1983. Springer, Berlin, Heidelberg, 1985. 1–198.
- Yihong Wu. Lecture notes for ECE598YW: Information-theoretic methods for high-dimensional statistics. 2017.
- Peter J. Bickel and Yaacov Ritov. Estimating integrated squared density derivatives: sharp best order of convergence estimates. Sankhya: The Indian Journal of Statistics, Series A (1988): 381–393.
- Lucien Birgé and Pascal Massart. Estimation of integral functionals of a density. The Annals of Statistics 23.1 (1995): 11–29.
- Gérard Kerkyacharian and Dominique Picard. Estimating nonquadratic functionals of a density using Haar wavelets. The Annals of Statistics 24.2 (1996): 485-507.
- James Robins, Lingling Li, Rajarshi Mukherjee, Eric Tchetgen Tchetgen, and Aad van der Vaart. Higher order estimating equations for high-dimensional models. Annals of statistics 45, no. 5 (2017): 1951.