(Warning: These materials may be subject to lots of typos and errors. We are grateful if you could spot errors and leave suggestions in the comments, or contact the author at yjhan@stanford.edu.)
This lecture starts to talk about specific tools and ideas to prove information-theoretic lower bounds. We will temporarily restrict ourselves to statistical inference problems (which most lower bounds apply to), where the presence of randomness is a key feature in these problems. Since the observer cannot control the realizations of randomness, the information contained in the observations, albeit not necessarily in a discrete structure (e.g., those in Lecture 2), can still be limited. In this lecture and subsequent ones, we will introduce the reduction and hypothesis testingideas to prove lower bounds of statistical inference, and these ideas will also be applied to other problems.
1. Basics of Statistical Decision Theory
To introduce statistical inference problems, we first review some basics of statistical decision theory. Mathematically, let 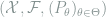

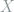
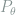
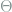
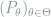
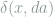



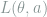

Definition 1 (Risk) Under the above notations, the risk of the decision rule
under loss function
and the true parameter
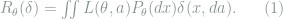
Intuitively, the risk characterizes the expected loss (over the randomness in both the observation and the decision rule) of the decision rule when the true parameter is 
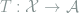

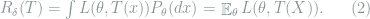
Example 1 In linear regression model with random design, let the observations
be i.i.d. with
and
. Here the parameter set
is a finite-dimensional Euclidean space, and therefore we call this model parametric. The quantity of interest is
of the linear estimator
.
Example 2 In density estimation model, let
be i.i.d. drawn from some
-Lipschitz density
supported on
. Here the parameter set

Example 3 By allowing general action spaces and loss functions, the decision-theoretic framework can also incorporate some non-statistical examples. For instance, in stochastic optimization
may parameterize a class of convex Lipschitz functions
, and
, and the loss function
![L(\theta, a) = f_\theta(a) - \min_{a^\star \in [0,1]^d} f_\theta(a^\star).](https://s0.wp.com/latex.php?latex=+L%28%5Ctheta%2C+a%29+%3D+f_%5Ctheta%28a%29+-+%5Cmin_%7Ba%5E%5Cstar+%5Cin+%5B0%2C1%5D%5Ed%7D+f_%5Ctheta%28a%5E%5Cstar%29.+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
In practice, one would like to find optimal decision rules for a given task. However, the risk is a function of
Definition 2 (Minimax and Bayes Decision Rule) The minimax decision rule is the decision rule
. The Bayes decision rule under distribution
(called the prior distribution) is the decision rule
.
It is typically hard to find the minimax decision rule in practice, while the Bayes decision rule admits a closed-form expression (although hard to compute in general).
Proposition 3 The Bayes decision rule under prior
is given by the estimator
where
denotes the posterior distribution of
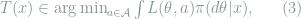
Proof: Left as an exercise for the reader. 
2. Deficiency and Model Distance
The central target of statistical inference is to propose some decision rule for a given statistical model with small risks. Similarly, the counterpart in the lower bound is to prove that certain risks are unavoidable for any decision rules. Here to compare risks, we may either compare the entire risk function, or its minimax or Bayes version. In this lecture we will focus on the risk function, and many later lectures will be devoted to appropriate minimax risks.
We start with the task of comparing two statistical models with the same parameter set 
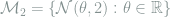
- There is no proper notion of noise for general (especially non-additive) statistical models;
- Even if a natural notion of noise exists for certain models, it is not necessarily true that the model with smaller noise is always better. For example, let
the modelhas a smaller magnitude of the additive noise. However, despite with a larger magnitude of the noise, the model
is actually noise-free since one can decode the perfect knowledge of

To overcome the above difficulties, we introduce the idea of model reduction. Specifically, we aim to establish the fact that for any decision rule in one model, there is another decision rule in the other model which is uniformly no worse than the former rule. The idea of reduction appears in many fields, e.g., in P/NP theory it is sufficient to work out one NP-complete instance (e.g., circuit satisfiability) from scratch and establish all others by polynomial reduction. This reduction idea is made precise via the following definition.
Definition 4 (Model Deficiency) For two statistical models
and
, we call
is
-deficient relative to
if for any finite subset
, any finite action space
, and any decision rule
based on model
based on model
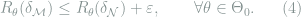
Note that the definition of model deficiency does not involve the specific choice of the action space and loss function, and the finiteness of 
Although Definition 4 gives strong performance guarantees for the 
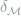
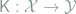
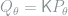
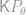


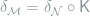
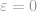
Theorem 5 Model
where
is the total variation distance between probability measures
and
.

Proof: The sufficiency part is easy. Given such a kernel
![\begin{array}{rcl} R_\theta(\delta_{\mathcal{M}}) - R_\theta(\delta_{\mathcal{N}}) &=& \iint L(\theta,a)\delta_\mathcal{N}(y,da) \left[\int P_\theta(dx)\mathsf{K}(dy|x)- Q_\theta(dy) \right] \\ &\le & \|Q_\theta - \mathsf{K}P_\theta \|_{\text{TV}} \le \varepsilon, \end{array}](https://s0.wp.com/latex.php?latex=+%5Cbegin%7Barray%7D%7Brcl%7D+R_%5Ctheta%28%5Cdelta_%7B%5Cmathcal%7BM%7D%7D%29+-+R_%5Ctheta%28%5Cdelta_%7B%5Cmathcal%7BN%7D%7D%29+%26%3D%26+%5Ciint+L%28%5Ctheta%2Ca%29%5Cdelta_%5Cmathcal%7BN%7D%28y%2Cda%29+%5Cleft%5B%5Cint+P_%5Ctheta%28dx%29%5Cmathsf%7BK%7D%28dy%7Cx%29-+Q_%5Ctheta%28dy%29+%5Cright%5D+%5C%5C+%26%5Cle+%26+%5C%7CQ_%5Ctheta+-+%5Cmathsf%7BK%7DP_%5Ctheta+%5C%7C_%7B%5Ctext%7BTV%7D%7D+%5Cle+%5Cvarepsilon%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
for the loss function is non-negative and upper bounded by one.
The necessity part is slightly more complicated, and for simplicity we assume that all 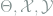
![\sup_{L(\theta,a),\pi(d\theta)} \inf_{\delta_{\mathcal{M}}}\iint L(\theta,a)\pi(d\theta)\left[\int \delta_\mathcal{M}(x,da)P_\theta(dx) - \int \delta_\mathcal{N}(y,da)Q_\theta(dy)\right] \le \varepsilon. \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=+%5Csup_%7BL%28%5Ctheta%2Ca%29%2C%5Cpi%28d%5Ctheta%29%7D+%5Cinf_%7B%5Cdelta_%7B%5Cmathcal%7BM%7D%7D%7D%5Ciint+L%28%5Ctheta%2Ca%29%5Cpi%28d%5Ctheta%29%5Cleft%5B%5Cint+%5Cdelta_%5Cmathcal%7BM%7D%28x%2Cda%29P_%5Ctheta%28dx%29+-+%5Cint+%5Cdelta_%5Cmathcal%7BN%7D%28y%2Cda%29Q_%5Ctheta%28dy%29%5Cright%5D+%5Cle+%5Cvarepsilon.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
Note that the LHS of (5) is bilinear in 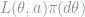
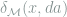

![\{M\in [0,1]^{\Theta\times \mathcal{A}}: \sum_\theta \|M(\theta, \cdot)\|_\infty \le 1 \}](https://s0.wp.com/latex.php?latex=%5C%7BM%5Cin+%5B0%2C1%5D%5E%7B%5CTheta%5Ctimes+%5Cmathcal%7BA%7D%7D%3A+%5Csum_%5Ctheta+%5C%7CM%28%5Ctheta%2C+%5Ccdot%29%5C%7C_%5Cinfty+%5Cle+1+%5C%7D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
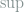
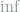
![\inf_{\delta_{\mathcal{M}}}\sup_{L(\theta,a),\pi(d\theta)}\iint L(\theta,a)\pi(d\theta)\left[\int \delta_\mathcal{M}(x,da)P_\theta(dx) - \int \delta_\mathcal{N}(y,da)Q_\theta(dy)\right] \le \varepsilon. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=+%5Cinf_%7B%5Cdelta_%7B%5Cmathcal%7BM%7D%7D%7D%5Csup_%7BL%28%5Ctheta%2Ca%29%2C%5Cpi%28d%5Ctheta%29%7D%5Ciint+L%28%5Ctheta%2Ca%29%5Cpi%28d%5Ctheta%29%5Cleft%5B%5Cint+%5Cdelta_%5Cmathcal%7BM%7D%28x%2Cda%29P_%5Ctheta%28dx%29+-+%5Cint+%5Cdelta_%5Cmathcal%7BN%7D%28y%2Cda%29Q_%5Ctheta%28dy%29%5Cright%5D+%5Cle+%5Cvarepsilon.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
By evaluating the inner supremum, (6) implies the existence of some 
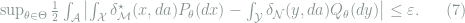
Finally, choosing 
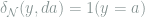
Based on the notion of deficiency, we are ready to define the distance between statistical models, also known as the Le Cam’s distance.
Definition 6 (Le Cam’s Distance) For two statistical models
is defined as the infimum of
such that
It is a simple exercise to show that Le Cam’s distance is a pesudo-metric in the sense that it is symmetric and satisfies the triangle inequality. The main importance of Le Cam’s distance is that it helps to establish equivalence between some statistical models, and people are typically interested in the case where 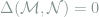
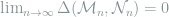
In the remainder of this lecture, I will give some examples of models whose distance is zero or asymptotically zero. In the next lecture it will be shown that regular models will always be close to some Gaussian location model asymptotically, and thereby the classical asymptotic theory of statistics can be established.
3. Equivalence between Models
3.1. Sufficiency
We first examine the case where 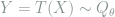
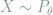
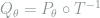

Theorem 7 Under the above setting,
if and only if
forms a Markov chain.
Note that the Markov condition
3.2. Equivalence between Multinomial and Poissonized Models
Consider a discrete probability vector 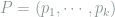

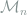
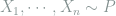

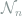
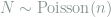

The next theorem shows that the multinomial and Poissonized models are asymptotically equivalent, which means that it actually does no harm to consider the more convenient Poissonized model for analysis, at least asymptotically. In later lectures I will also show a non-asymptotic result between these two models.
Theorem 8 For fixed
,
Proof: We only show that 
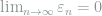

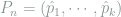




Let 
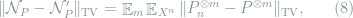
where 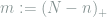

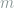
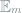


Lemma 9 Let
and
be the KL divergence and
-divergence, respectively. Then
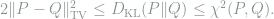
The proof of Lemma 9 will be given in later lectures when we talk about joint ranges of divergences. Then by Lemma 9 and Jensen’s inequality,

Since by simple algebra,

then by (8) we obtain that
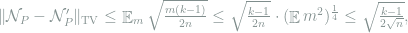
which goes to zero uniformly in 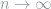
Remark 1 In fact, the following non-asymptotic characterization
could be established. This result is contained in an upcoming paper.
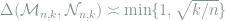
3.3. Equivalence between Nonparametric Regression and Gaussian White Noise Models
A well-known problem in nonparametric statistics is the nonparametric regression:
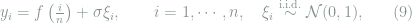
where the underlying regression function 
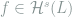
![\mathcal{H}^s(L) := \left\{f\in C[0,1]: \sup_{x\neq y}\frac{|f^{(m)}(x) - f^{(m)}(y)| }{|x-y|^\alpha} \le L\right\},](https://s0.wp.com/latex.php?latex=+%5Cmathcal%7BH%7D%5Es%28L%29+%3A%3D+%5Cleft%5C%7Bf%5Cin+C%5B0%2C1%5D%3A+%5Csup_%7Bx%5Cneq+y%7D%5Cfrac%7B%7Cf%5E%7B%28m%29%7D%28x%29+-+f%5E%7B%28m%29%7D%28y%29%7C+%7D%7B%7Cx-y%7C%5E%5Calpha%7D+%5Cle+L%5Cright%5C%7D%2C+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
with ![s=m+\alpha, m\in {\mathbb N}, \alpha\in (0,1]](https://s0.wp.com/latex.php?latex=s%3Dm%2B%5Calpha%2C+m%5Cin+%7B%5Cmathbb+N%7D%2C+%5Calpha%5Cin+%280%2C1%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
There is also a continuous version of (9) called the Gaussian white noise model, where a process ![(Y_t)_{t\in [0,1]}](https://s0.wp.com/latex.php?latex=%28Y_t%29_%7Bt%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
![dY_t = f(t)dt + \frac{\sigma}{\sqrt{n}}dB_t, \qquad t\in [0,1], \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=+dY_t+%3D+f%28t%29dt+%2B+%5Cfrac%7B%5Csigma%7D%7B%5Csqrt%7Bn%7D%7DdB_t%2C+%5Cqquad+t%5Cin+%5B0%2C1%5D%2C+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
where ![(B_t)_{t\in [0,1]}](https://s0.wp.com/latex.php?latex=%28B_t%29_%7Bt%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
Let 
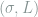
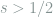
Theorem 10 If
Proof: Consider another Gaussian white noise model 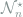

![f^\star(t) = \sum_{i=1}^n f\left(\frac{i}{n}\right) 1\left(\frac{i-1}{n}\le t<\frac{i}{n}\right), \qquad t\in [0,1].](https://s0.wp.com/latex.php?latex=+f%5E%5Cstar%28t%29+%3D+%5Csum_%7Bi%3D1%7D%5En+f%5Cleft%28%5Cfrac%7Bi%7D%7Bn%7D%5Cright%29+1%5Cleft%28%5Cfrac%7Bi-1%7D%7Bn%7D%5Cle+t%3C%5Cfrac%7Bi%7D%7Bn%7D%5Cright%29%2C+%5Cqquad+t%5Cin+%5B0%2C1%5D.+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
Note that under the same parameter
![\begin{array}{rcl} D_{\text{KL}}(P_{Y_{[0,1]}^\star} \| P_{Y_{[0,1]}}) &=& \frac{n}{2\sigma^2}\int_0^1 (f(t) - f^\star(t))^2dt\\ & =& \frac{n}{2\sigma^2}\sum_{i=1}^n \int_{(i-1)/n}^{i/n} (f(t) - f(i/n))^2dt \\ & \le & \frac{L^2}{2\sigma^2}\cdot n^{1-2(s\wedge 1)}, \end{array}](https://s0.wp.com/latex.php?latex=+%5Cbegin%7Barray%7D%7Brcl%7D+D_%7B%5Ctext%7BKL%7D%7D%28P_%7BY_%7B%5B0%2C1%5D%7D%5E%5Cstar%7D+%5C%7C+P_%7BY_%7B%5B0%2C1%5D%7D%7D%29+%26%3D%26+%5Cfrac%7Bn%7D%7B2%5Csigma%5E2%7D%5Cint_0%5E1+%28f%28t%29+-+f%5E%5Cstar%28t%29%29%5E2dt%5C%5C+%26+%3D%26+%5Cfrac%7Bn%7D%7B2%5Csigma%5E2%7D%5Csum_%7Bi%3D1%7D%5En+%5Cint_%7B%28i-1%29%2Fn%7D%5E%7Bi%2Fn%7D+%28f%28t%29+-+f%28i%2Fn%29%29%5E2dt+%5C%5C+%26+%5Cle+%26+%5Cfrac%7BL%5E2%7D%7B2%5Csigma%5E2%7D%5Ccdot+n%5E%7B1-2%28s%5Cwedge+1%29%7D%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
which goes to zero uniformly in 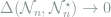
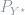
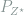
![\begin{array}{rcl} \frac{dP_Y}{dP_Z}((Y_t^\star)_{t\in [0,1]}) &=& \exp\left(\frac{n}{2\sigma^2}\left(\int_0^1 2f^\star(t)dY_t^\star-\int_0^1 f^\star(t)^2 dt \right)\right) \\ &=& \exp\left(\frac{n}{2\sigma^2}\left(\sum_{i=1}^n 2f(i/n)(Y_{i/n}^\star - Y_{(i-1)/n}^\star) -\int_0^1 f^\star(t)^2 dt \right)\right). \end{array}](https://s0.wp.com/latex.php?latex=+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cfrac%7BdP_Y%7D%7BdP_Z%7D%28%28Y_t%5E%5Cstar%29_%7Bt%5Cin+%5B0%2C1%5D%7D%29+%26%3D%26+%5Cexp%5Cleft%28%5Cfrac%7Bn%7D%7B2%5Csigma%5E2%7D%5Cleft%28%5Cint_0%5E1+2f%5E%5Cstar%28t%29dY_t%5E%5Cstar-%5Cint_0%5E1+f%5E%5Cstar%28t%29%5E2+dt+%5Cright%29%5Cright%29+%5C%5C+%26%3D%26+%5Cexp%5Cleft%28%5Cfrac%7Bn%7D%7B2%5Csigma%5E2%7D%5Cleft%28%5Csum_%7Bi%3D1%7D%5En+2f%28i%2Fn%29%28Y_%7Bi%2Fn%7D%5E%5Cstar+-+Y_%7B%28i-1%29%2Fn%7D%5E%5Cstar%29+-%5Cint_0%5E1+f%5E%5Cstar%28t%29%5E2+dt+%5Cright%29%5Cright%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
As a result, under model ![f \rightarrow (n(Y_{i/n}^\star - Y_{(i-1)/n}^\star))_{i\in [n]}\rightarrow (Y_t^\star)_{t\in [0,1]}](https://s0.wp.com/latex.php?latex=f+%5Crightarrow+%28n%28Y_%7Bi%2Fn%7D%5E%5Cstar+-+Y_%7B%28i-1%29%2Fn%7D%5E%5Cstar%29%29_%7Bi%5Cin+%5Bn%5D%7D%5Crightarrow+%28Y_t%5E%5Cstar%29_%7Bt%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
![(n(Y_{i/n}^\star - Y_{(i-1)/n}^\star))_{i\in [n]}](https://s0.wp.com/latex.php?latex=%28n%28Y_%7Bi%2Fn%7D%5E%5Cstar+-+Y_%7B%28i-1%29%2Fn%7D%5E%5Cstar%29%29_%7Bi%5Cin+%5Bn%5D%7D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
![(y_i)_{i\in [n]}](https://s0.wp.com/latex.php?latex=%28y_i%29_%7Bi%5Cin+%5Bn%5D%7D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
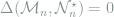
3.4. Equivalence between Density Estimation and Gaussian White Noise Models
Another widely-used model in nonparametric statistics is the density estimation model, where samples
Compared with the previous results, a slightly more involved result is that the density estimation model, albeit with a seemingly different form, is also asymptotically equivalent to a proper Gaussian white noise model. However, here the Gaussian white noise model should take the following different form:
![dY_t = \sqrt{f(t)}dt + \frac{1}{2\sqrt{n}}dB_t, \qquad t\in [0,1]. \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=+dY_t+%3D+%5Csqrt%7Bf%28t%29%7Ddt+%2B+%5Cfrac%7B1%7D%7B2%5Csqrt%7Bn%7D%7DdB_t%2C+%5Cqquad+t%5Cin+%5B0%2C1%5D.+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
In other words, in nonparametric statistics the problems of density estimation, regression and estimation in Gaussian white noise are all asymptotically equivalent, under certtain smoothness conditions.
Let
Theorem 11 If
Proof: Instead of the original density estimation model, we actually consider a Poissonized sampling model 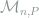
![(Z_t)_{t\in [0,1]}](https://s0.wp.com/latex.php?latex=%28Z_t%29_%7Bt%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
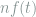


Fix an equal-spaced grid 

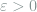

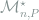
![f^\star(t) = \sum_{i=1}^M f(t_i) 1\left(t_{i-1}\le t<t_i\right), \qquad t\in [0,1].](https://s0.wp.com/latex.php?latex=+f%5E%5Cstar%28t%29+%3D+%5Csum_%7Bi%3D1%7D%5EM+f%28t_i%29+1%5Cleft%28t_%7Bi-1%7D%5Cle+t%3Ct_i%5Cright%29%2C+%5Cqquad+t%5Cin+%5B0%2C1%5D.+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
As long as 
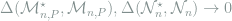
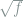


![Z_i = \sum_{j=1}^N 1(t_{i-1}\le X_j<t_i) \sim \text{Poisson}\left(n^\varepsilon f(t_i) \right), \quad i\in [m]](https://s0.wp.com/latex.php?latex=+Z_i+%3D+%5Csum_%7Bj%3D1%7D%5EN+1%28t_%7Bi-1%7D%5Cle+X_j%3Ct_i%29+%5Csim+%5Ctext%7BPoisson%7D%5Cleft%28n%5E%5Cvarepsilon+f%28t_i%29+%5Cright%29%2C+%5Cquad+i%5Cin+%5Bm%5D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
is sufficient. Moreover, under the model 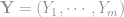
![Y_i = \sqrt{nm}(Y_{t_i} - Y_{t_{i-1}}) \sim \mathcal{N}\left(\sqrt{n^\varepsilon f(t_i)}, \frac{1}{4}\right), \quad i\in [m]](https://s0.wp.com/latex.php?latex=+Y_i+%3D+%5Csqrt%7Bnm%7D%28Y_%7Bt_i%7D+-+Y_%7Bt_%7Bi-1%7D%7D%29+%5Csim+%5Cmathcal%7BN%7D%5Cleft%28%5Csqrt%7Bn%5E%5Cvarepsilon+f%28t_i%29%7D%2C+%5Cfrac%7B1%7D%7B4%7D%5Cright%29%2C+%5Cquad+i%5Cin+%5Bm%5D+&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
is also sufficient. Further, all entries of 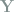

To do so, a first attempt would be to find a bijective mapping 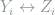
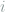
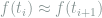

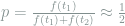

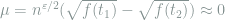
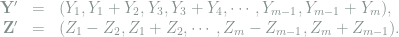
Note that 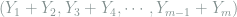
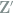

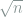
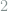

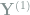
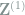
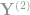
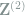
Remark 2 Experienced readers may have noticed that these are the wavelet coefficients under the Haar wavelet basis, where superscripts
Next we are ready to describe the randomization procedure. For notational simplicity we will write 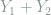
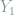
For entries in 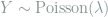
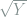

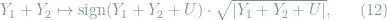
where ![U\sim \text{Uniform}([-1/2,1/2])](https://s0.wp.com/latex.php?latex=U%5Csim+%5Ctext%7BUniform%7D%28%5B-1%2F2%2C1%2F2%5D%29&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
For entries in 

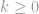


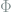
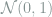
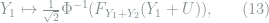
where again 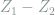
The approximation properties of these transformations are summarized in the following theorem.
Theorem 12 Sticking to the specific examples of
, let
be the respective distributions of the RHS in (12) and (13), and
be the respective distributions of
and
, we have
where
is some universal constant, and
denotes the Hellinger distance.
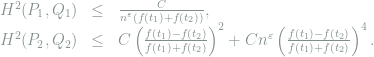
The proof of Theorem 12 is purely probabilitistic and involved, and is omitted here. Applying Theorem 12 to the vector 

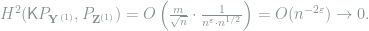
As for the vector 
![\ell\in [\ell_{\max}]](https://s0.wp.com/latex.php?latex=%5Cell%5Cin+%5B%5Cell_%7B%5Cmax%7D%5D&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
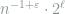
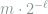
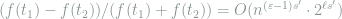
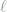


Since 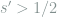

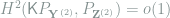
4. Bibliographic Notes
The statistical decision theory framework dates back to Wald (1950), and is currently the elementary course for graduate students in statistics. There are many excellent textbooks on this topic, e.g., Lehmann and Casella (2006) and Lehmann and Romano (2006). The concept of model deficiency is due to Le Cam (1964), where the randomization criterion (Theorem 5) was proved. The present form is taken from Torgersen (1991). We also refer to the excellent monographs by Le Cam (1986) and Le Cam and Yang (1990).
The asymptotic equivalence between nonparametric models has been studied by a series of papers since 1990s. The equivalence between nonparametric regression and Gaussian white noise models (Theorem 10) was established in Brown and Low (1996), where both the fixed and random designs were studied. It was also shown in a follow-up work (Brown and Zhang 1998) that these models are non-equivalent if 
- Abraham Wald, Statistical decision functions. Wiley, 1950.
- Erich L. Lehmann and George Casella, Theory of point estimation. Springer Science & Business Media, 2006.
- Erich L. Lehmann and Joseph P. Romano, Testing statistical hypotheses. Springer Science & Business Media, 2006.
- Lucien M. Le Cam, Sufficiency and approximate sufficiency. The Annals of Mathematical Statistics (1964): 1419-1455.
- Erik Torgersen, Comparison of statistical experiments. Cambridge University Press, 1991.
- Lucien M. Le Cam, Asymptotic methods in statistical theory. Springer, New York, 1986.
- Lucien M. Le Cam and Grace Yang, Asymptotics in statistics. Springer, New York, 1990.
- Lawrence D. Brown and Mark G. Low, Asymptotic equivalence of nonparametric regression and white noise. The Annals of Statistics 24.6 (1996): 2384-2398.
- Lawrence D. Brown and Cun-Hui Zhang, Asymptotic nonequivalence of nonparametric experiments when the smoothness index is
. The Annals of Statistics 26.1 (1998): 279-287.
- Lawrence D. Brown, Andrew V. Carter, Mark G. Low, and Cun-Hui Zhang, Equivalence theory for density estimation, Poisson processes and Gaussian white noise with drift. The Annals of Statistics 32.5 (2004): 2074-2097.
- Kolyan Ray, and Johannes Schmidt-Hieber, The Le Cam distance between density estimation, Poisson processes and Gaussian white noise. arXiv preprint arXiv:1608.01824 (2016).
In Example 2, should it say “all possible 1-Lipschitz densities” rather than “functions”?
Yes! Thanks for pointing this out.
so hard to learn