By Carlos Gomez Uribe
Recently, I stumbled upon a well-known result in Quantum Mechanics (QM) while taking a class on the topic that seemed to scream information theory (IT). Being new to QM, I was unaware of any connections to IT beyond quantum communications, and what I was looking at clearly wasn’t about that. It turns out there is at least one more obvious and strong connection between these areas, which is not, surprisingly, based on the Shannon-entropy-related concepts that pervade IT. Rather, it is the less information-theory-popular Fisher information that plays a prominent role in QM. The fuller results can be found in the pdf below:
Introduction
Information theory is the theory underpinning all of our digital communications: the storing, sending, and receiving of bits so widespread in our digital society, whether these describe songs, movies, photos, or this post. The starring concepts in Information theory are the so-called Shannon entropy, and its related quantities, e.g., the Kullback-Leibler (KL) distance between two probability distributions, or the mutual information.
In addition to defining the communication technology of our times, connections and cross-pollination between information theory and machine learning and statistics appear ever more regularly. For example, it is now well known that strategies for parameter estimation for broad classes of useful statistical models models, ranging from maximum likelihood for simpler models to variational inference for more complex models, turn out to be equivalent to minimization of the KL distance with appropriately chosen arguments. Information theory concepts have also inspired research and ways of thinking in biology, particularly in neuroscience and in signaling pathways, where in some cases it is obvious that organisms (including unicellular ones) survive and thrive only by reliably communicating external information about their environment to their control center (the brain or the nucleus).
It is similarly well known that the entropy of statistical mechanics is related to Shannon’s entropy, but I was unaware of additional connections between physics and information theory. Until recently, when I stumbled upon a well-known result in QM for the simple harmonic oscillator (SHO). The state of lowest energy in a QM system is called the ground state. Determining the ground state is one of the core problems in QM for general systems, partly since other excited states of the system can be more readily found from the ground state.
For the SHO, the ground state is readily found by minimizing the expected energy of the system, resulting in a Gaussian distribution for the oscillator’s position. But the Gaussian distribution also solves the well-known IT problem of maximizing the entropy with a known variance, and the optimization problem itself looks very similar to the minimization of energy problem in the SHO. Could it be true more generally that finding the ground state of a QM system is equivalent to maximizing the entropy given appropriate system-specific constraints? Unfortunately, it seems like the answer is no. However, the corresponding explorations helped me learn many things I did not know about the Fisher information, including the prominent role it plays in QM.
Quantum Mechanics
Arguably the simplest system to learn QM describes a single spin-less particle evolving in a single spatial dimension 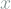
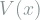
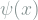

Interestingly, position and momentum are are both functions of the same wave function in QM. The probability of measuring a certain momentum 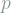
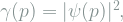
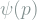

Wave functions generally depend on time too, and evolve according to the Schrodinger equation 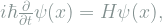
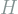
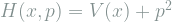
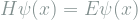
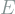
One often finds that there are an infinite but countable number of eigenfunctions. Any arbitrary wave function can then be expressed as a linear combination of all of the eigenfunctions. The ground state is the eigenfunction with the smallest eigenvalue, i.e., that which achieves the smallest energy with certainty. Equivalently, the ground state 
![E[H] = E[V(x)] + E[p^2] = E[V(x)] + \sigma_p^2 + E[p]^2 ,](https://s0.wp.com/latex.php?latex=E%5BH%5D+%3D++E%5BV%28x%29%5D+%2B+E%5Bp%5E2%5D+%3D+E%5BV%28x%29%5D+%2B+%5Csigma_p%5E2+%2B+E%5Bp%5D%5E2+%2C&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
![E[]](https://s0.wp.com/latex.php?latex=E%5B%5D+&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
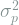
![\psi_o(x) = \arg \min_\psi E[H]](https://s0.wp.com/latex.php?latex=%5Cpsi_o%28x%29+%3D+%5Carg+%5Cmin_%5Cpsi+E%5BH%5D+&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
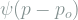
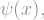

![E[p] = 0](https://s0.wp.com/latex.php?latex=E%5Bp%5D+%3D+0&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
![E[x] = 0.](https://s0.wp.com/latex.php?latex=E%5Bx%5D+%3D+0.&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
![\psi_o(x) = \arg \min_\psi E[V(x)] + \sigma_p^2,](https://s0.wp.com/latex.php?latex=%5Cpsi_o%28x%29+%3D+%5Carg+%5Cmin_%5Cpsi++E%5BV%28x%29%5D+%2B+%5Csigma_p%5E2%2C&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
![E[V(x)]](https://s0.wp.com/latex.php?latex=E%5BV%28x%29%5D+&bg=ffffff&fg=7f8d8c&s=1&c=20201002)

Now for the interesting part, also an implication of the Fourier relationship between ![\sigma_p^2 = E[|\nabla \log \psi(x)|^2] = \frac{1}{4}E[|\nabla \log \rho(x)|^2] = J(x)/4,](https://s0.wp.com/latex.php?latex=%5Csigma_p%5E2+%3D+E%5B%7C%5Cnabla+%5Clog+%5Cpsi%28x%29%7C%5E2%5D+%3D++%5Cfrac%7B1%7D%7B4%7DE%5B%7C%5Cnabla+%5Clog+%5Crho%28x%29%7C%5E2%5D+%3D+J%28x%29%2F4%2C+&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
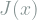

![J(x) = E[|\frac{\partial}{\partial \theta}\log \rho(x - \theta)|^2] = E[|\frac{\partial}{\partial x}\log \rho(x - \theta)|^2] =E[|\frac{\partial}{\partial x}\log \rho(x )|^2],](https://s0.wp.com/latex.php?latex=J%28x%29+%3D+E%5B%7C%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%5Ctheta%7D%5Clog+%5Crho%28x+-+%5Ctheta%29%7C%5E2%5D+%3D++E%5B%7C%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+x%7D%5Clog+%5Crho%28x+-+%5Ctheta%29%7C%5E2%5D+%3DE%5B%7C%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+x%7D%5Clog+%5Crho%28x+%29%7C%5E2%5D%2C&bg=ffffff&fg=7f8d8c&s=0&c=20201002)
![\psi_o(x) = \arg \min_\psi E[V(x)] + J(x)/4,](https://s0.wp.com/latex.php?latex=%5Cpsi_o%28x%29+%3D+%5Carg+%5Cmin_%5Cpsi++E%5BV%28x%29%5D+%2B+J%28x%29%2F4%2C&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
Now, think of the space of wave function as the union of subspaces of wave functions with a specific expected potential energy, say ![E[V(x)] = v .](https://s0.wp.com/latex.php?latex=E%5BV%28x%29%5D+%3D+v+.&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
![E[V(x)] = v ,](https://s0.wp.com/latex.php?latex=E%5BV%28x%29%5D+%3D+v+%2C&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
For the SHO, 
![E[H] = \sigma_x^2 + J(x)/4 .](https://s0.wp.com/latex.php?latex=E%5BH%5D+%3D+%5Csigma_x%5E2+%2B+J%28x%29%2F4+.&bg=ffffff&fg=7f8d8c&s=1&c=20201002)
An appealing conjecture then is whether maximizing entropy given constraints is equivalent to minimizing the Fisher information given the same constraints. Unfortunately, the general answer is no. It still seems, however, like the answer is generally that the two problems are not equivalent. E.g., Appendix A of the book Physics from Fisher Information by Frieden (a book full of interesting ideas and observations) claims that these problems only coincide for the SHO and not otherwise.
Additional Learnings
Reading and thinking about this was fun, and made me learn several things about the Fisher information I didn’t know or had not thought about, including:
- Unlike the Shannon entropy, the Fisher information captures the local behavior of its functional argument. Take your favorite continuous distribution, e.g., a Gaussian, and compute its Shannon entropy. Now break your space into chunks, shuffle them around, and compute the entropy of the resulting shuffled distribution. You’ll find that the entropy remains unchanged, even though your distribution looks nothing like the one you started with. Now try the same experiment using the Fisher information. You will find that it is significantly changed, because it is a function of the derivative of the function, which has now multiple points of discontinuity.
- Just like the Shannon entropy leads to derived useful concepts like the KL distance between distributions, the Fisher information also has derived concepts that can be similarly useful. E.g., the relative Fisher information is the analog to the KL distance between two distributions, and is given by
for any two distributions
and
. There is also a Fisher mutual information which is what you probably already expect by now. See “Fisher Information Properties” by Pablo Zegers for examples and more on these quantities, including a Fisher data processing inequality.
- Unlike the Shannon entropy, it is easy to work with the Fisher information even when you only have an unnormalized distribution, a very common situation, e.g., when working with any undirected graphical model where the normalization is expensive or impossible to compute. This is because the integrand in the Fisher information
is independent of normalization.
- There are several known interesting relations between the Fisher information and the Shannon entropy. The best known shows that adding an independent zero-mean Gaussian with a small variance
to a random variable, increases the Shannon entropy of the random variable by half its Fisher information times
- There is much ongoing work in QM to better understand the properties and behaviors of the Fisher information, also known there as the Weizsacker energy. Accessible examples include the articles “On the realization of quantum Fisher information” by Aparna Saha from 2017, or “The Fisher information of single-particle systems with a central potential” by Romera et al. from 2005.
- The properties above have lead to a few promising articles in machine learning that develop learning methods based on Fisher information, starting with a series of articles including “Estimation of Non-Normalized Statistical Models by Score Matching” by Aapo Hyvarinen. There, one also finds Fisher informations based not on a location parameter but on a scale parameter, resulting in a Fisher information where the integrand is
(note the extra
) that is useful for distributions on the positive real line. Generally, I bet that revisiting the learning methods where the KL distance is used as part or all of the underlying optimization objective, and adding the corresponding relative Fisher distance or replacing the KL distance by the relative Fisher distance, will result in useful new learning algorithms. Similarly, it is possible that some of these algorithms could then help find the ground states in QM.
Overall, I expect the Fisher information still has much to contribute to science, statistics and machine learning. For example, how does the analog of variational inference work when using the relative Fisher information instead of KL? Does it lead to efficient and useful algorithms, or is the resulting optimization problem and plausible relaxations of it too complex?
If you want to read up some more on related topics here are some suggestions:
- A more complete and clear summary of my explorations.
- Information theory in Biology. Chapter 6 in the Biophysics book by William Bialek is all about Shannon entropy in cell Biology. I have not yet seen any work based on Fisher information in this context.
- Statistical mechanics and information theory. The classic paper is “Information Theory and Statistical Mechanics” by Jaynes.
- Several uncertainty relations based on several concepts of entropy, though not including Fisher information: “Entropic Uncertainty Relations and their Applications” by Coles et al.
Teaching About Information With Rocks
On a completely separate note, this class set up an Information Theory night in an elementary school in Palo Alto. Knowing kids interest in rocks, I brought a rock collection with crystals, fossils, etc. and used the rocks as an excuse to get the kids engaged. After letting them explore the rock collection, talking about which rocks they liked and why, how diverse the rocks are, etc. we played a version of the Guess Who game. In the first round, I would pick in my mind a rock out of the collection, and a kid got to ask me yes/no questions about the rock. In the second round, the roles would reverse, and the winner was the person who guessed the rock picked by the other player in the fewest questions. Then we talked about which kinds of questions seemed to eliminate the largest number of remaining rock candidates, and told them those questions reveal more information than questions that tend to eliminate only few of the remaining candidates. I think it worked out pretty well, as explaining more abstract topics to kids and keeping their interest while you do it, can be a challenge.